

PythonでExcelファイルを読み込む方法について。
複数のシートがある場合に、シート名を指定して読み込む方法や、読み込み時にヘッダーになる行をや列を指定する方法についてパターン別に実例を用いて解説しています。
必要なライブラリのインストール
Pythonでexcelファイルを読み込むためには、xlrdとpandasというライブラリが必要になります。
pip installコマンドを使ってインストールを行います。
pip install -U xlrd
pip install -U pandas- xlrd
– excelファイルを読み込むライブラリ
– 対象ファイルの拡張子:「.xls」「.xlsx」 - pandas
– データ分析用のライブラリ
– この中のread_excelメソッドを使います。
pipについては以下をご参考ください。
>【python】pipとは?コマンド一覧と使い方を実例で解説
読み込むExcelファイルの用意
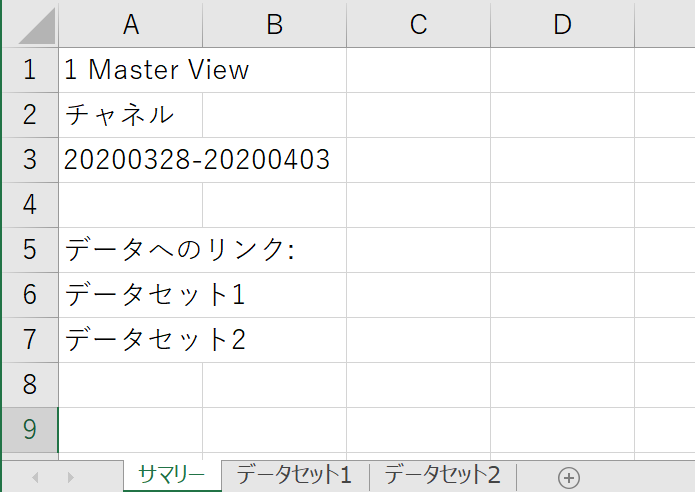
ここでは例として、以下のような3枚のシートをもつExcelファイルを表データとして読み込みます。
・3枚のシートを含む表
・ファイルパス「~/desktop/GA-demo.xlsx」
Excelファイルの読み込み
PythonのPandasモジュールでExcelファイルを読み込にはread_excelメソッドを使います。Excelファイルの読み込み方法には、大きく3つのパターンにがあります。
- read_excelのデフォルト設定の読み込み
- シート番号で読み込み
- シート名で読み込み
read_excelメソッドの基本構文と使い方
read_excelメソッドの基本構文は、第一引数にファイルパスを指定し、第二引数以下でオプションを指定する形になっています。
オプションは省略可能です。
pandas.read_excel('ファイルパス', オプション=値)使うためにはインポートしたpandasモジュールをオブジェクトとして指定する必要があります。
一般的に、pandasモジュールはpdという省略名称(エイリアス)でインポートすることが多いです。また、読み込んだデータは変数に格納します。
Pandasの表形式のオブジェクトをDataFrameと呼ぶため、変数にdfを使うことが多いです。(エイリアス名も変数名も任意です)
import pandas as pd
df = pd.read_excel('ファイルパス', オプション=値)read_excelのデフォルト設定の読み込み
read_excelメソッドのデフォルト設定は、1枚目のシートを読み込む設定になっています。
import pandas as pd
df = pd.read_excel('~/desktop/GA-demo.xlsx')
df
デスクトップにあるGA-demo.xlsxファイルの1枚目のシートがPythonに読み込まれました。
デフォルトでは1行目がヘッダーとして読み込まれます。これを変更するには、headerオプションを使います(後述)。
シート番号で読み込み
オプションに sheet_name=n を記述することで、指定したシートを読み込むことができます。
- 「n」:シート番号。
- シート番号は0始まり。(1枚目のシートを読み込みたい場合は0を指定する)
import pandas as pd
pd.read_excel('~/desktop/GA-demo.xlsx', sheet_name=1)
sheet_name=1を指定しているので、2枚目のシートを読み込みます。
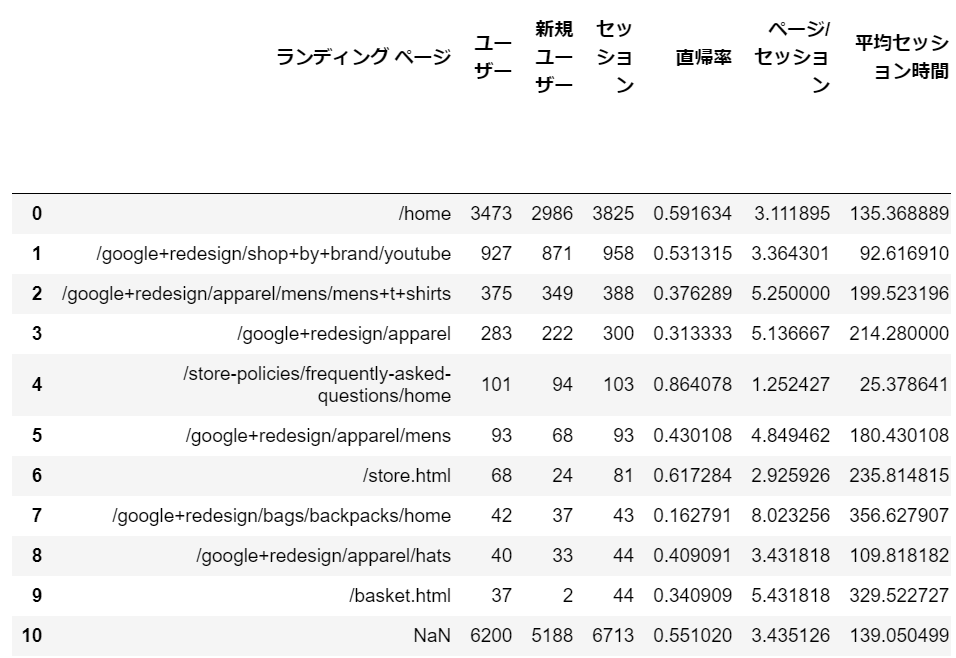
デスクトップにあるGA-demo.xlsxファイルの2枚目のシートがPythonに読み込まれました。
シート名で読み込み
オプションに sheet_name=’シート名’ を記述することで、指定したシートを読み込むことができます。
import pandas as pd
pd.read_excel('~/desktop/GA-demo.xlsx', sheet_name='データセット2')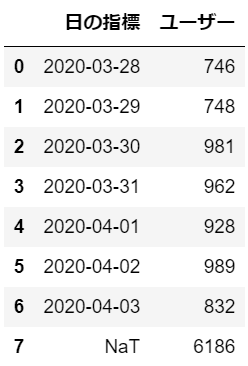
デスクトップにあるGA-demo.xlsxファイルのシート名「データセット2」がPythonに読み込まれました。
read_excelメソッド主要オプション一覧
| オプション | 使用例 | 内容 |
|---|---|---|
| sheet_name=整数 | sheet_name=0 | 指定した番号のシートを読み込む(0始まり) |
| sheet_name=’文字列’ | sheet_name=’分析表’ | 指定した名前のシートを読み込む |
| header | header=1 | ヘッダー行の指定(デフォルトは推測、ない場合 header=None ※「N」は大文字) |
| names | ①names=[‘AA’,’BB’,’CC’,,] ②names=’1234567′ | 列タイトルを付ける(ヘッダーがある場合は「header=0」と併用) |
| index_col | index_col=0 | 行の見出し(index)となる列を指定 |
| usecols | usecols=[1,2,5] | 読み込む行を指定。1行のみでもリスト形式で指定「usecols=[0]。列タイトルでも指定可能」 |
| dtype | dtype=str | 型を指定して読み込み。適用できない場合はエラー(strをfloatで読み込むなど) |
| skiprows | ①skiprows=5 ②skiprows=[1,3,6] | 冒頭で読み込まない行番号を指定。整数の場合は0から指定した整数まで。 |
| skipfooter | skipfooter=2, engine=’python’, encoding=’utf_8′ | 下から除外する行数を指定。pythonで使うことを記述する必要あり。文字化けする場合は文字コードを指定。 |
| nrows | nrows=5 | 何行目まで読み込むかを指定。 |
| na_values | na_values=[‘string1’, ‘string2’] | 指定した値をNaNとして読み込む。 |
| comment | comment=’#’ | 指定した値があるセルの後ろのデータを読み込まない。該当セルをNoneとし、後ろのデータをNaNとする。 |
read_excelメソッドのシート名やシート番号を指定して読み込む以外の主要オプションについて以下で補足しています。
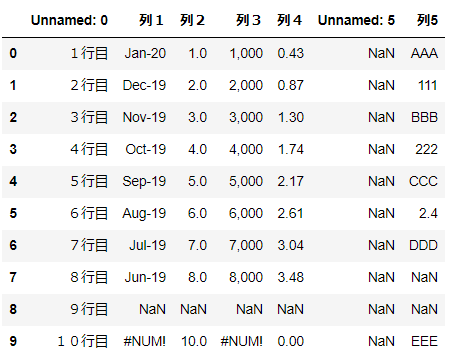
元となる表
各種オプションの実行結果を実例で示すにあたり、例として以下の表を使います。
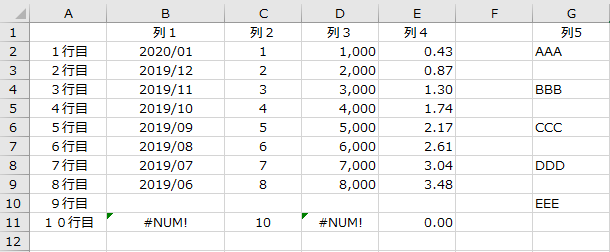
▼列
・A列がindex(見出し)
・F列が空
・G列が文字と空白セル
▼行
・1行目が列のタイトル
・9行目が空
・10行目に数式エラー(#NUM!)がある
■読み込み結果
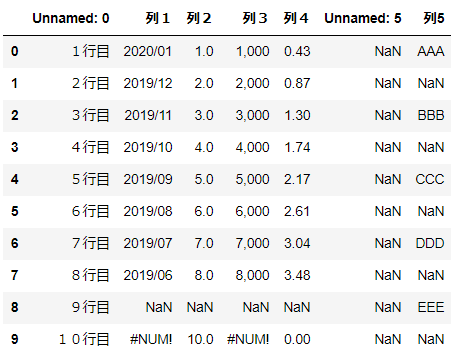
▼ポイント
・1列目に見出し列が追加(0からのindex番号)
・1行目にタイトル行が追加
- 空白のセルは「Unnamed:列番号」で補完
・空白セルはNaNになる。
・数式エラーは #NUM!のまま表示される。
※追加内容は再度ファイルに出力する場合に残る。(NaNは消える)
各列の属性(objectやfloat64)
各列の属性は次のようになります。
Unnamed: 0 object
列1 object
列2 float64
列3 object
列4 float64
Unnamed: 5 float64
列5 object
・日付:object型
・数値:float64型
└ 整数・少数どちらも
└ NaNは無視される
・関数エラーがある列:object型
・空の列:float64型
・テキスト:object型
└ テキストセルが1個あればobject型になる
元ファイルの空白行・列・セル
空白は「NaN」(空データ)として処理されます。
下記もNaNとして扱われます。
- 「”」
- 「#N/A」
- 「#N/A N/A」
- 「#NA」
- 「-1.#IND」
- 「-1.#QNAN」
- 「-NaN」
- 「-nan」
- 「1.#IND」
- 「1.#QNAN」
- 「」
- 「N/A」
- 「NA」
- 「NULL」
- 「NaN」
- 「n/a」
- 「nan」
- 「null」
ヘッダーの読み込みと指定
デフォルトの読み込み結果
読み込み時デフォルトは「類推」となっています。(Pandasが自動で割り当てる)
※基本的に最上部の行がヘッダーとして読み込まれます。
▼元ファイル
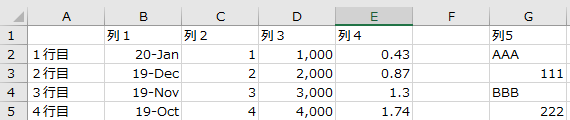
▼読み込み結果
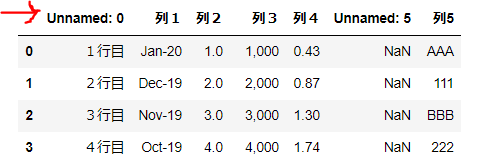
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx')
dfpd.read_excelでデスクトップのtest.xlsxファイルを読み込み、変数dfに格納しています。
ヘッダーがないファイルの読み込み
ヘッダーがないファイルの読み込むには、オプションでヘッダーがないことを指定します。
pd.read_excelの第2引数に以下を記述します。
header=None※NoneのNは大文字です。(noneはエラーになります)
▼元ファイル(「デスクトップのtest2.xlsx」とする)
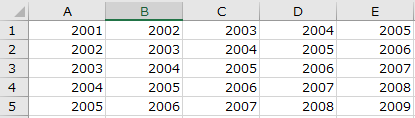
▼読み込みファイル
pd.read_excel(‘~/desktop/test.xlsx’ ,header=None)
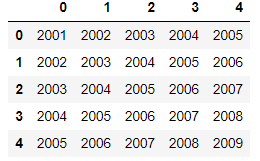
import pandas as pd
df= pd.read_excel('~/desktop/test.xlsx' ,header=None)
df指定がない場合(デフォルト)
ヘッダーのないファイルを読み込むときにheader=Noneを指定しないと、一番上の行がヘッダーとして読み込まれてしまいます。
df2 = pd.read_excel(‘~/desktop/test2.xlsx’)
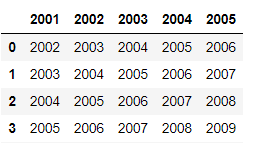
ヘッダーとなる行を指定する方法
ヘッダーとなる行を指定するには、オプションで header=整数 を記述します。
このとき、指定した行より上は読み込まれません。
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx', header=6)
df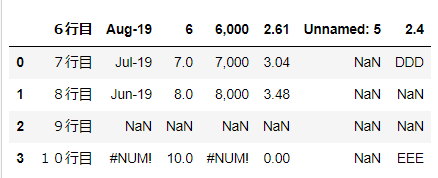
指定がない場合(デフォルト)
ヘッダー名を指定して読み込む方法
読み込み時にヘッダーの名前を指定して読み込むことができます。方法オプションでnames=を記述します。
オプションの値の書き方は2種類あります。
- 連続した文字列
- list形式
- 既にheaderがある場合は、
header=0で上書きします。 - 読み込む列数より指定文字数が少ない場合は、前方の不足分の列タイトルが空白になります。
- 指定文字数の方が多い場合は、後方の列タイトルがNaNになります。
- 異なる列に同じ名前は付けられません(エラーになります)
実例:7列あるデータ
(1)連続した文字列で指定
▼例1:names='123345'の場合
7列あるデータに対して5つの文字しか指定しない場合、不足分の前方2列のヘッダー名は空白になります。
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx' ,names='12345')
df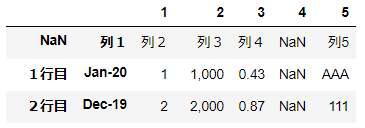
先頭の足りない2列分が空白になる。
▼例2:names='abcdefghi'の場合
7列あるデータに対して9つの文字を指定すると、過剰な分がNaNのデータをもった列として追加されます。
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx' ,names='abcdefghi')
df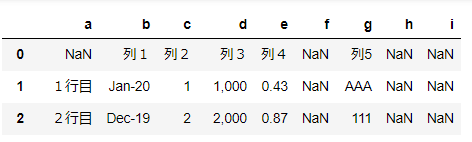
余剰な2列は中身が空(NaN)の列となる。
▼例3:names=’aaabbbccc’重複する場合はエラー
指定する列名が重複する場合はエラーになります。
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx' ,names='aaabbbccc')
df
#出力
# ValueError: Duplicate names are not allowed.(2)list形式で指定
ヘッダー名を1語ではなく単語を指定したい場合は配列(list)を使います。
▼例1:names=[‘aaa’,’bbb’,’ccc’,’ddd’,’eee’,’fff’]の場合
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx' ,names=['aaa','bbb','ccc','ddd','eee','fff'])
df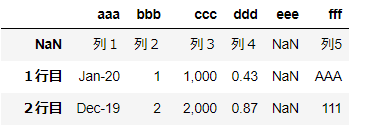
▼例2:names=[‘aaa’,’bbb’,’aaa’,’ddd’] 重複はエラー
指定する列名が重複する場合はエラーになります。
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx' ,names=['aaa','bbb','aaa','ddd'])
df見出し列(インデックス)の指定
これまではヘッダーとなる行の設定でした。同様に、見出しとなる列(インデックス)も指定することができます。
見出し列(インデックス)の指定は、オプションにindex_col=整数を記述します。デフォルトは自動でインデックス番号が振られた列が追加されます。
例:index_col=0 とした場合
index_col=0とすれば、一番左端の列が見出しとして読み込まれます。
python
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx' ,index_col=0)
df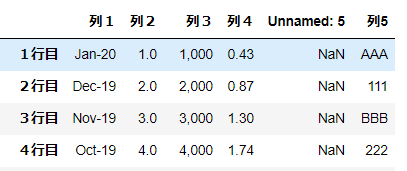
指定なし(デフォルト)の場合
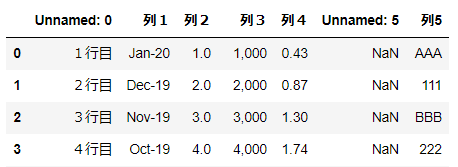
読み込む列を指定する
表を読み込むときに、列番号または列名で指定することができます。(指定した列しか読み込まない)
- 列番号で指定
- 列名で指定
▼元のExcelファイルは以下を使用
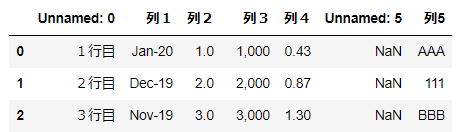
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx')
df列番号で指定する方法
オプションにusecols=[]を記述
└ リスト型
└ 指定が1列の場合でも[]で記述複数列指定
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx', usecols=[0,3,6])
df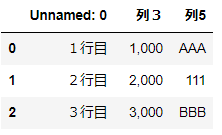
▼1列の場合(例 0番目の列のみ)
usecols=[0]
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx', usecols=[0])
df
▼list型でない場合はエラー
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx', usecols=0)
df
#出力
# ValueError: 'usecols' must either be list-like of all strings, all unicode, all integers or a callable.
列名で指定する方法
列名を指定して抜き出すことも可能です。
▼例:usecols=[‘列1’,’列4’]
└ 列1と列4を指定。
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx', usecols=['列1','列4'])
df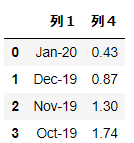
▼読み込み時に列名をつけて、その名前で抜き出すことも可能です。
例:
・header=0
・names=’ABCDEFG’
・usecols=[‘A’,’C’]
header=0で既存のヘッダーの設定をリセットし、namesでヘッダーに名前をつけ、usecolsで使う列名を指定しています。
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx', header=0, names='ABCDEFG' ,usecols=['A','C'])
df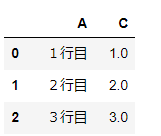
行の読み込み
行を読み込む方法は以下の4つがあります。
- 先頭から読み込む行数を指定
- 先頭から除外する行数を指定
- 指定した行を除外
- 末尾から除外する行数を指定
先頭から読み込む行数を指定する方法
オプションにnrows=整数を記述します。
行数が膨大にある時に、中身を確認する場合などに便利です。
▼例:nrows=3
上から3行目まで読み込む。
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx', nrows=3)
df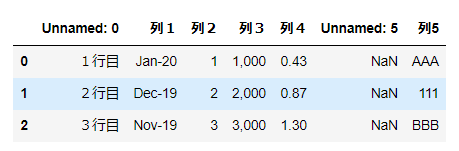
先頭から除外する行数を指定する方法
オプションに skiprows=整数 を記述します。
▼例:skiprows=6
上から6行目までスキップ。
ヘッダーの指定がなければ、6行目がヘッダーになる。
※「skiprows=0」はスキップなし。
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx', skiprows=6)
df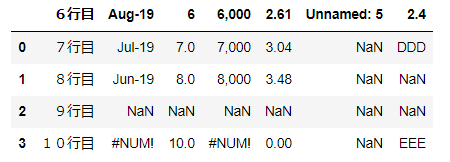
指定した行を除外する方法
オプションにskiprows=[整数]を記述します。
▼例:skiprows=[2,3,6,7,8]
上から2,3,6,7,8行目をスキップ。
※1行のみスキップする場合も[ ]を使う
└「skipworw=[6]」:6行目をスキップ
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx', skiprows=[2,3,6,7,8])
df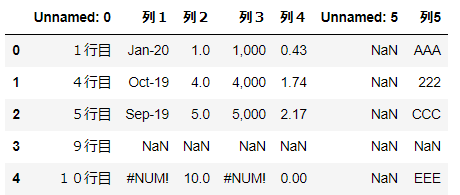
末尾から除外する行数を指定
オプションにskipfooter=整数, engine=’python’を記述します。
※文字化けする場合は文字コードを指定してください。
例:encoding=’utf_8′
▼例:skipfooter=6, engine=’python’, encoding=’utf_8’
下から6行目までをスキップ。
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx', skipfooter=6, engine='python', encoding='utf_8')
df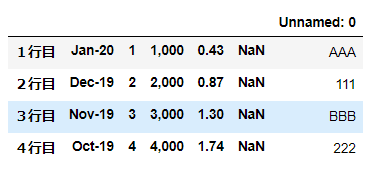
▼文字コードの指定がない場合
文字コードの指定がない場合は文字化けすることがあります。
skipfooter=6, engine=’python’
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx', skipfooter=6, engine='python')
df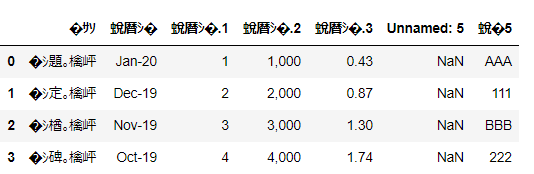
日本語が文字化けしています。
▼pythonの指定がない場合
engine=’python’の指定がない場合はエラーが発生します。
skipfooter=6
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx', skipfooter=6)
df
#出力
# <ipython-input-81-77b6fdc5c66e>:2: ParserWarning: Falling back to the 'python' engine
#because the 'c' engine does not support skipfooter;
#you can avoid this warning by specifying engine='python'.エラーで「engine=’python’」を記述する指示があります。
型を指定して読み込む
オプションでdtype=型を記述します。
変更できない場合はエラーになります。
※読み込んだ表のタイプを見る方法に「dtypes」メソッドがあります。
「dtype」と「dtypes」は複数形か単数形かで処理が異なるので注意してください。
▼dtype=strで文字列に変換し、.dtypes(dtypesメソッド)で型を確認する例。
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx', dtype=str)
df.dtypes
#出力
Unnamed: 0 object
列1 object
列2 object
列3 object
列4 object
Unnamed: 5 object
列5 object
dtype: object
▼デフォルト
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx')
df.dtypes
#出力
Unnamed: 0 object
列1 object
列2 float64
列3 object
列4 float64
Unnamed: 5 float64
列5 object
dtype: object
▼文字列をfloatに変換
文字列をfloatに変換しようとするとエラーになる。
import pandas as pd
df = pd.read_excel('~/desktop/test.xlsx' ,dtype=float)
df.dtypes
#出力
# ValueError: could not convert string to floatWEB上のファイルの読み込み
WEB上のExcelファイルを読み込むこともできます。
pd.read_excel(‘URL’, encoding=’文字コード’)
※文字化けする場合や、文字コードが異なるというエラーが出た場合は「encoding=’文字コード’」を指定してください。
▼例:政府の全国の都道府県別男女別人口の統計データを読み込み
・参考ページ:e-Start
import pandas as pd
dfurl = pd.read_excel('https://www.e-stat.go.jp/stat-search/file-download?statInfId=000031524010&fileKind=1', encoding='shift_jis')
dfurl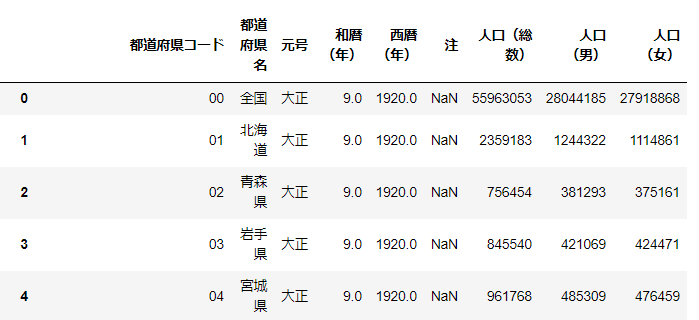
文字コードの指定がない場合はエラーになる
encoding=’shift_jis’など文字コードの指定がない場合はエラーになります。
import pandas as pd
dfurl = pd.read_excel('https://www.e-stat.go.jp/stat-search/file-download?statInfId=000031524010&fileKind=1')
dfurl
#出力
# UnicodeDecodeError: 'utf-8' codec can't decode byte 0x93 in position 0: invalid start byte
