

AWSのEC2上でpythonのseleniumを使って指定したURLの要素を抜き出すまでの一連の流れをまとめています。
実施手順
スクレイピングにあたって実行するのは次の6つのステップになります。
- chromeドライバーのインストール
- chromeのインストール
- seleniumのインストール
- 日本語フォントのインストール
- 指定したURLのテキストを抜き出す(text.py)
- 指定したURLの画面キャプチャを取得(capture.py)
前提
・sshを使ってEC2インスタンスに接続済み。
・python3インストール済み。
1.chromeドライバーのインストール
①ChromeDriverのオフィシャルページからDLしたいバージョンのDLページに移動。
②linux64用のリンクのアドレスをコピー。
③DLし解凍
#tmpディレクトリに移動
$ cd/tmp/
#chromedriverをダウンロード(URLはコピペ)
$ wget https://chromedriver.storage.googleapis.com/83.0.4103.39/chromedriver_linux64.zip
#解凍
$ unzip chromedriver_linux64.zip
#解凍したファイルを /user/bin配下に移動
$ sudo mv chromedriver /usr/bin/chromedriver2.chromeのインストール
#chromeのインストール
$ curl https://intoli.com/install-google-chrome.sh | bash
Complete! <-インストール成功
Successfully installed Google Chrome!
#ファイル名を変更
$ sudo mv /usr/bin/google-chrome-stable /usr/bin/google-chrome
#バージョンの確認
$ google-chrome --version && which google-chrome
Google Chrome 83.0.4103.61 <- --versionの実行結果
/usr/bin/google-chrome <- whichの実行結果3.seleniumのインストール
$ pip3 install selenium4.日本語フォントのインストール
$ sudo yum install ipa-gothic-fonts ipa-mincho-fonts ipa-pgothic-fonts ipa-pmincho-fonts日本語フォントをインストールしておかないと、画面をキャプチャした際に文字化けが発生します。
5.指定したURLのテキストを抜き出す(text.py)
①ユーザーフォルダにtext.pyファイルを作成
$ cd ~
$ touch text.py
$ vi text.py②vimエディタが立ち上がるので以下をコピペ。
└ 「i」キーで挿入モードに入る。
└ コピペは「shift+ins」(もしくは右クリックでpasteを選択)
#-*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
driver = webdriver.Chrome(options=options)
#URLの指定
driver.get("https://www.google.co.jp/")
#スクレイピングする要素を指定
element_text = driver.find_element_by_id("hptl").text
print(element_text)
driver.quit()③貼り付けが終わったら下記でvimエディタを保存し終了。esc + :wq + Enter
④作成したファイルを実行
$ python3 text.py
#下記が表示されれば成功
Googleについて ストア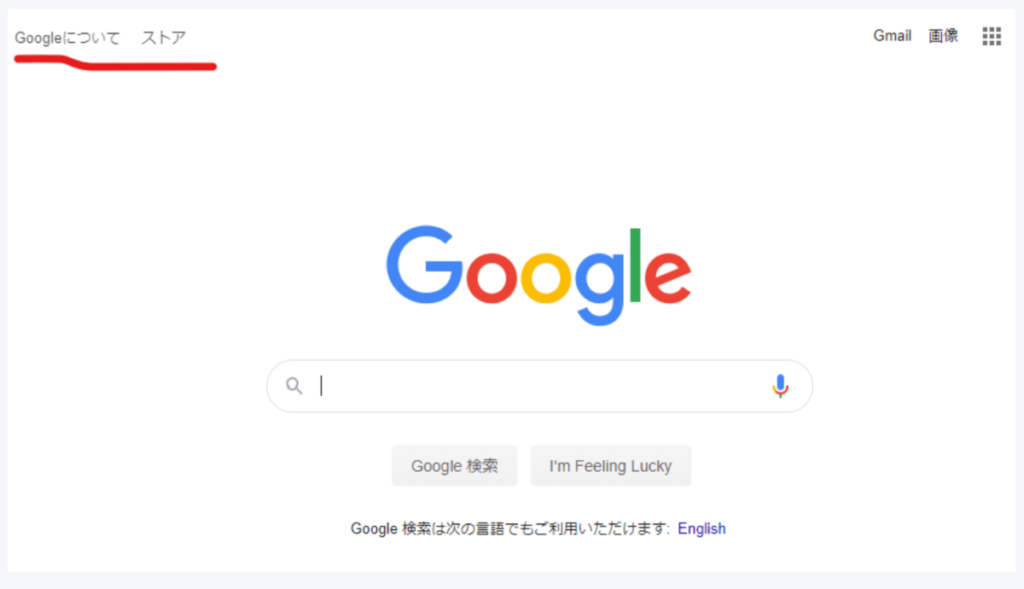
googleトップの右上のテキストをスクレイピング完了。
指定したURLの画面キャプチャを取得(capture.py)
①ユーザーフォルダにcaputure.pyファイルを作成
$ cd ~
$ touch capture.py
$ vi capture.py②vimエディタが立ち上がるので以下をコピペ。
└ 「i」キーで挿入モードに入る。
└ コピペは「shift+ins」(もしくは右クリックでpasteを選択)
#-*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
#キャプチャする画面サイズを指定
options.add_argument('--window-size=1280,1024')
driver = webdriver.Chrome(options=options)
#URLを指定
driver.get("https://www.google.co.jp/")
#キャプチャのファイル名と拡張子を指定
driver.save_screenshot('googletop.png')
driver.quit()③貼り付けが終わったら下記でvimエディタを保存し終了。esc + :wq + Enter
④作成したファイルを実行
$ python3 capture.py
#同一ディレクトリに下記ファイルができていれば成功
$ ls
googletop.png
以上で完了です。割とシンプルにスクレイピングすることができます。
後は対象のURL変えたり、抜き出す要素を変更するなど自由にカスタマイズしてください。

