

Pythonでcsvやexcelファイルを読み込むときに、空白セルがあると欠損値(NaN)として読み込まれます。
そのような、欠損値(NaN)が含まれる行や列を探したり、削除したり、変換する方法を実例を用いて解説しています。
使用する元データ
実例で解説するにあたり、以下のような6行6列のcsvファイルを読み込んでいます。
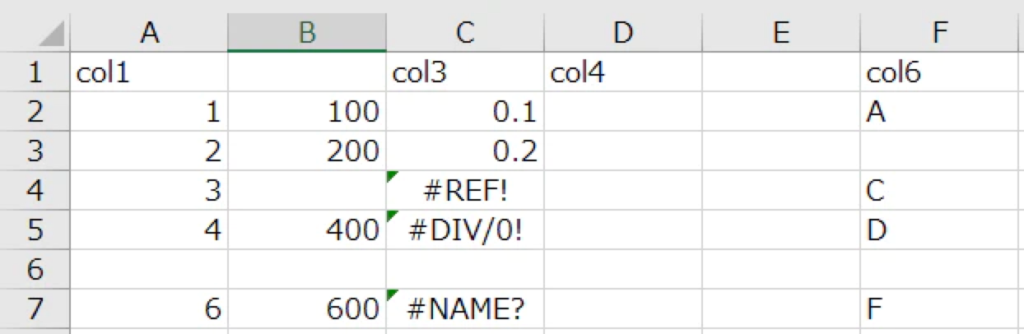
空白の行と列、行名や列名、セル、および、数式エラー「#REF!」「#DIV/0!」「#NAME?」を含めています。
読み込んだデータは df という変数に格納しています。
(参考)デスクトップにあるtest.csvファイルを読み込む方法
Pythonでのcsvファイルは以下で行います。
import pandas as pd
df = pd.read_csv('~/desktop/test.csv')
df
Pythonでのcsvファイルの読み込みの詳細は下記ご参考ください。
- csvファイルを読み込む方法を実例でわかりやすく解説(pandasのread_csvの使い方注意点とポイント)
- csvファイルの読み込みを使いこなす。pandas.read_csvの主要オプション一覧(文字化けの対処法、行列型の指定、WEB上のファイル読み込み方法など)
読み込んだデータ
DataFrameで読み込んだデータは以下のようになります。
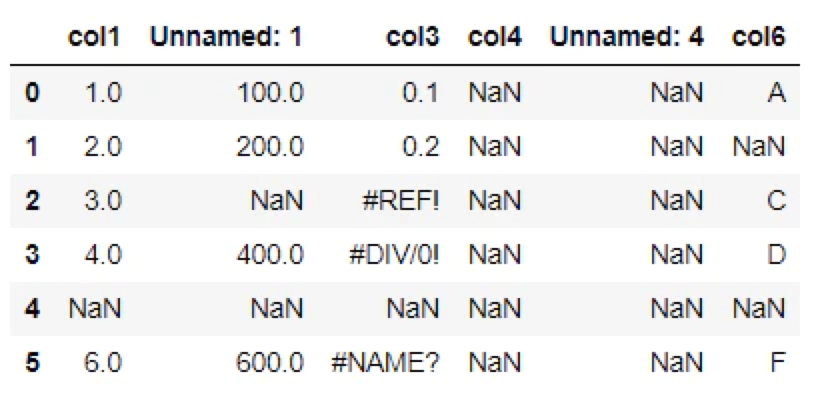
・空白セルが「NaN」となる。
・数式エラー「#REF!」「#DIV/0!」「#NAME?」は欠損値として認識されない(元のまま)。
・1行目がヘッダーとして認識される
欠損値を含む要素・行列の特定方法
欠損値を含む要素・行列の特定方法する方法には、isnaメソッドとisnullメソッドを使う方法があります。
- isna()
- isna().all()
- isna().any()
- isna().all().any()
- isna().any().any()
- isnull()
- 要素の特定はisnaメソッドを使う。
- 行か列のすべてがNaNか調べるには、isnaメソッドとallメソッドを組み合わせる。
- 行か列の要素の中にNaNがあるか調べるにはisnaメソッドとanyメソッドを組み合わせる。
- isnullメソッドはisnaメソッドのエイリアス(別名)。公式ページではisnaをメインで使用している。
isna()
各要素がNaNか調べる場合に使用します。NaNの場合は「True」、そうでない場合は「False」が返ります。(ブール型:booleanと呼びます)
NaNか調べる対象範囲は表全体を調べる方法と、範囲を指定する方法があります。検索結果を表形式で返すことをマッピングと言います。
- 表全体をマッピングする場合の対象オブジェクトは表データになります。df.isna()
- 範囲ををマッピングする場合の対象オブジェクトはPandasモジュールになります。 pd.isna([対象範囲])
表全体をマッピングする方法
df.isna()「df」:表データを格納した変数(変数名は任意です)
▼出力結果
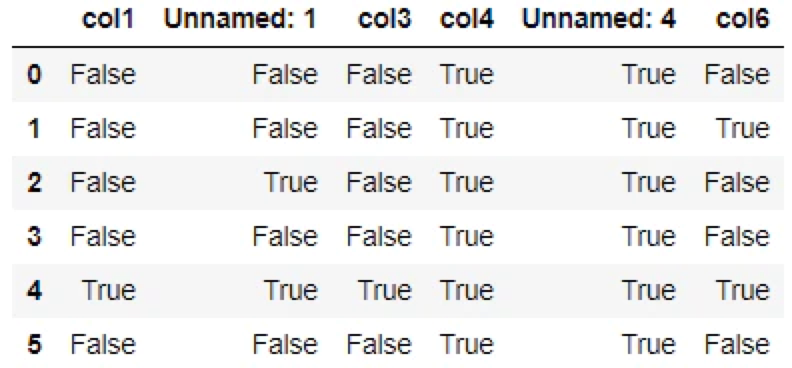
▼元のデータ
特定の行、列、要素でマッピングする方法
対象範囲を指定して検証(マッピング)することができます。この場合、isnaメソッドのオブジェクトはPandasになります。
Pandasをpdとしてインポートしている場合は以下の記述になります。
import pandas as pd
pd.isna(指定範囲)引数に表データの指定範囲を渡します。表データの範囲を指定する方法は以下をご参考ください。
(参考)【Python】表から行・列・値を取得&変更する方法を実例で解説
例: 指定列をマッピング
pd.isna(df['col1'])
#出力
0 False
1 False
2 False
3 False
4 True
5 False
Name: col1, dtype: bool
例: 指定行をマッピング
pd.isna(df.loc[[3]])
▽出力結果

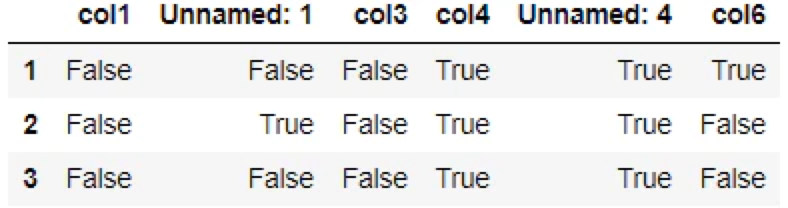
例: 複数の行をマッピング
pd.isna(df[1:4])
▽出力結果
例: 指定セルを判定
pd.isna()の「( )」の中でセルを指定した表データ入れると、そのセル自体がNaNかどうか判定した結果をTrueかFalseで返します。(NaNの場合はTrueになります)
セルの指定にはlocメソッドを使います。locメソッドは行列名で指定する方法と、番号で指定する方法があります。
- pd.isna(df.loc[行名, 列名])
- pd.isna(df.loc[行番号, 列番号])
(1) 行名「0」、列名「col4」のセルを判定
pd.isna(df.loc['0','col4'])
#出力
#True(2) 行番号「1」、列番号「3」のセルを判定
pd.isna(df.iloc[1,3])
#出力
#Trueisna().all()
行か列のすべてがNaNか調べるには、isnaメソッドとallメソッドを組み合わせます。中身がすべてNaNとなっている、行または列を一覧で表示してくれます。
該当すればTrue。非該当ならFalseになります。
対象が行か列かは、オプション「axis=1」の有無で切り替えます。
・df.isna().all():列の一覧
・df.isna().all(axis=1):行の一覧
元の表
すべての列の検証と結果
df.isna().all()
df.isna().all()
#出力
col1 False
Unnamed: 1 False
col3 False
col4 True
Unnamed: 4 True
col6 False
dtype: bool列名「col4」と「Unnamed: 4」のすべての要素がNaNになっていることがわかります。
すべての行の検証と結果
df.isna().all(axis=1)
df.isna().all(axis=1)
0 False
1 False
2 False
3 False
4 True
5 False
dtype: bool行4のすべての要素がNaNになっていることがわかります。
isna().any()
行か列の要素の中にNaNがあるか調べるにはisnaメソッドとanyメソッドを組み合わせます。
検証結果を一覧で表示し、中身に一つでもNaNを含む行または列をTrueとします。
対象が行か列かは、オプション「axis=1」の有無で切り替えます。
・df.isna().any():列の一覧
・df.isna().any(axis=1):行の一覧
元の表
NaNを含む列があるか検証
df.isna().any()
#出力
col1 True
Unnamed: 1 True
col3 True
col4 True
Unnamed: 4 True
col6 True
dtype: boolすべての列にNaNが含まれていることがわかります。
NaNを含む行があるか検証
df.isna().any(axis=1)
df.isna().any(axis=1)
0 True
1 True
2 True
3 True
4 True
5 True
dtype: boolすべての行にNaNが含まれていることがわかります。
isna().all().any()
表の中にすべて空白の列が一つでもある場合は、Trueをない場合はFalseを返します。
表の状態をサクッと見たいときに使えます。
df.isna().all().any()
#出力
# True処理内容の詳細
まず、isna().allで列の要素の全てがNaNがあるかを調べて一覧化したデータを作成します。すべての要素がNaNの場合はTrueになります。
df.isna().all()
#出力
col1 False
Unnamed: 1 False
col3 False
col4 True
Unnamed: 4 True
col6 False
dtype: bool次に、any()を上記の実行結果に対して行い、一つでもTrueがある場合はTrueを、ない場合はFalseを返します。
空白列が一つでもあるか確認するときに使います。
isna().all(axis=1).any()
表の中にすべて空白の行が一つでもある場合は、Trueをない場合はFalseを返します。allメソッドのオプションで「axis=1」を指定しています。
表の状態をサクッと見たいときに使えます。
df.isna().all(axis=1).any()
#出力
# True
処理内容の詳細
まず、isna(axis=1).allで行の要素の全てがNaNがあるかを調べて一覧化したデータを作成します。すべての要素がNaNの場合はTrueになります。
df.isna().all(axis=1)
0 False
1 False
2 False
3 False
4 True
5 False
dtype: bool次に、any()を上記の実行結果に対して行い、一つでもTrueがある場合はTrueを、ない場合はFalseを返します。
空白行が一つでもあるか確認するときに使います。
isna().any().any()
表の中に一つでもNaNがある場合はTrue、ない場合はFalseを返します。
df.isna().any().any()
#出力
# True処理内容の詳細
まず、isna().anyで列の要素に1つでもNaNがあるかを調べて一覧化したデータを作成します。要素が1つでもNaNの場合はTrueになります。
df.isna().any()
#出力
col1 True
Unnamed: 1 True
col3 True
col4 True
Unnamed: 4 True
col6 True
dtype: bool次に、any()を上記の実行結果に対して行い、一つでもTrueがある場合はTrueを、ない場合はFalseを返します。
なお、isna(axis=1).any().any() でも同じ結果になります。
isnull()
isnullメソッドは、isnaメソッドのエイリアス(別名)です。
上記のisnaをisnullに置き換えても全く同じ処理になります。
参考リンク
Pandas公式の各メソッドの説明は以下になります(英語)
– isna()
– all()
– any()
– isnull()
欠損値の数をカウントする方法
欠損値NaNの数をカウントする方法は以下のメソッドが使えます。
- isna().sum()
- isna().sum().sum()
- len() – count()
isna().sum()
各行または列にNaNが何個含まれるかをカウントします。
行か列かは、オプション「axis=1」の有無で切り替えます。
・df.isna().sum():列ごとのカウント数
・df.isna().sum(axis=1):行ごとのカウント数
各列のNaNをカウント
df.isna().sum()
df.isna().sum()
#出力
col1 1
Unnamed: 1 2
col3 1
col4 6
Unnamed: 4 6
col6 2
dtype: int64行のNaNをカウント
df.isna().sum(axis=1)
df.isna().sum(axis=1)
#出力
0 2
1 3
2 3
3 2
4 6
5 2
dtype: int64isna().sum().sum()
表全体に含まれているNaNの数をカウントします。
df.isna().sum().sum()
#出力
# 18処理内容の詳細
まず、 isna().sum()で各行ごとのNaNの数をカウントしています。
df.isna().sum()
#出力
col1 1
Unnamed: 1 2
col3 1
col4 6
Unnamed: 4 6
col6 2
dtype: int64次に、sum()を上記の実行結果に対して行い、全てを足し合わせた結果を返します。
なお、isna().sum(axis=1).sum() でも同じ結果になります。
len() – count()
lenメソッドとcountメソッドを使うことで、指定した行または列のNaNの数を求めことができます。
対象は一列または一行のみです。
len(df['行名']) - count(df['行名'])
▼実施していること
①len(df['行名'])
└ 指定した行の要素の数をカウント
②count(df['行名'])
└ 指定した行に含まれるNaN以外の要素数
① – ②とすることで、指定した行に含まれるNaNの数を算出する。
<補足>
countメソッド:NaN以外の要素の数をカウント
▼対象列(NaNが2つ含まれる列。列名:col6)対象とする列
df.col6
0 A
1 NaN
2 C
3 D
4 NaN
5 F
▼実行結果指定した行に含まれるNaNの数
len(df['col6'])-df['col6'].count()
#出力
# 2
欠損値の削除
dropnaメソッドを使うことで、欠損値NaNを削除することができます。
dropnaのオプション一覧
| オプション | 内容 |
|---|---|
| axis=0 | 行(省略可) |
| axis=1 | 列 |
| how=’any’ | NaNが一つでもあれば削除(省略可) |
| how=’all’ | すべてNaNなら削除 |
| thresh=n | NaNでない(有効な)セルがn個以上なら削除しない |
| subset=[‘A’,,] | 指定した列名にNaNを含む行を削除(指定した列名からNaNを除去) |
| subset=[‘a’,,], axis=1 | 指定した行名にNaNを含む列を削除(指定した行名からNaNを除去) |
| inplace=True | 上書きを許可する |
▼元となる表
以下のようなDataFrameの表を対象にdropnaメソッドの実行結果を紹介しています。
すべてが欠損値の行や列を削除する方法
すべてが欠損値の行や列を削除するには、オプションで「how=’all’」を指定します。行か列どちらを指定するかはaxisオプションを使います。
- 行の削除: axis=0(デフォルトの設定。省略可能)
- 列の削除: axis=1
- 行列を削除: dropna(how=’all’).dropna(how=’all’, axis=1)
行の削除: axis=0(デフォルトの設定。省略可能)
・空白を含む「行」を削除。
・デフォルトが「axis=0」
以下2つは同じ処理になります。
dropna(how=’all’)
dropna(how=’all’, axis=0)
df.dropna(how='all')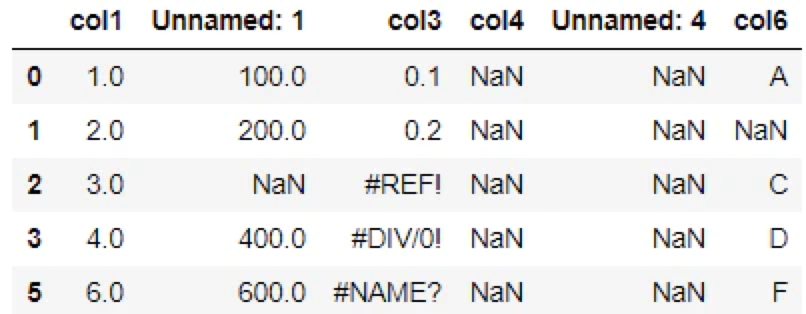
行4が削除されています。
列の削除: axis=1
dropna(how=’all’, axis=1) とすることですべての要素がNaNになっている列を削除することができます。
dropna(how='all', axis=1)▽出力
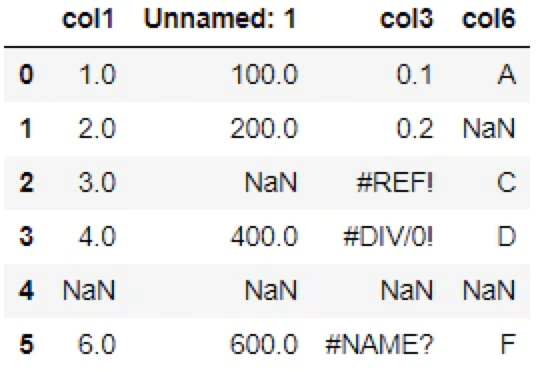
「col4」と「Unnamed: 4」の2列が削除されています。
行列を削除: dropna(how=’all’).dropna(how=’all’, axis=1)
dropna(how=’all’)とdropna(how=’all’, axis=1)を合わせて実行することで、要素の全てが空白の行と列を削除することができます。
このようにメソッドをつなげることをメソッドチェーンと言います。
dropna(how=’all’)で空白行の削除を実行後、
dropna(how=’all’, axis=1)で空白列を削除。空白行と列を削除
df.dropna(how='all').dropna(how='all', axis=1)▽出力
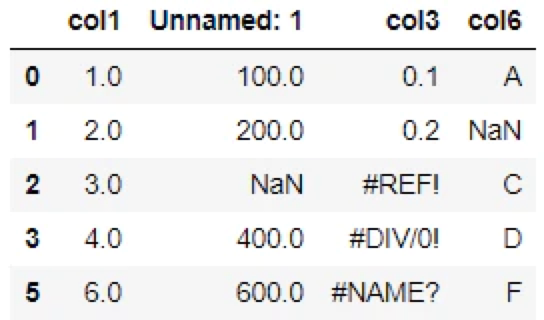
「行4」「列col4」「Unnamed: 4」が削除されています。
欠損値を一つでも含む行列を削除する方法
dropnaメソッドはデフォルトで、欠損値を一つでも含む行列を削除する処理になっています。
- 行を削除: dropna()
- 列を削除: dropna(axis=1)
- オプションで「how=’any’」を指定(デフォルト。省略可能)
- 行 or 列の指定はaxisで行う。
- 元の表は上書きされない(オプションで上書き設定もできます)
▼元となる表
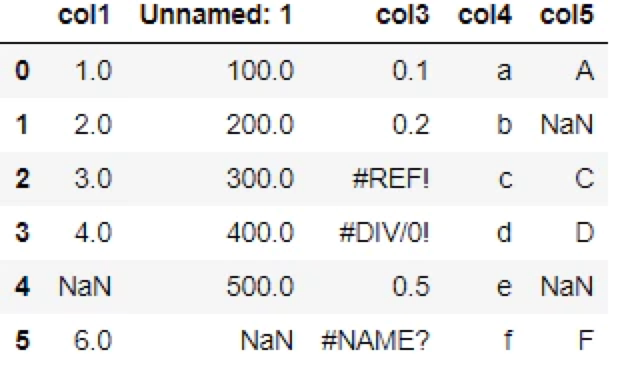
NaNは4つ。
(行,列)=(4,1), (5,2), (1,5), (4,5)
行を削除: dropna()
一つでもNaNを含む行を削除します。
dropnaメソッドのデフォルトはオプションでhow='any'が指定された状態となっています。下記3つは同じ処理になります。
dropna()
dropna(how=’any’)
dropna(how=’any’, axis=0)
▼実行例

いずれも、NaNを含む、1, 4, 5, 6行目が削除されています。
列を削除: dropna(axis=1)
1つでもNaNを含む列を削除します。
how=’any’は省略可のため、下記2つは同じ処理になります。
dropna(axis=1)
dropna(how=’any’, axis=1)
▼実行例
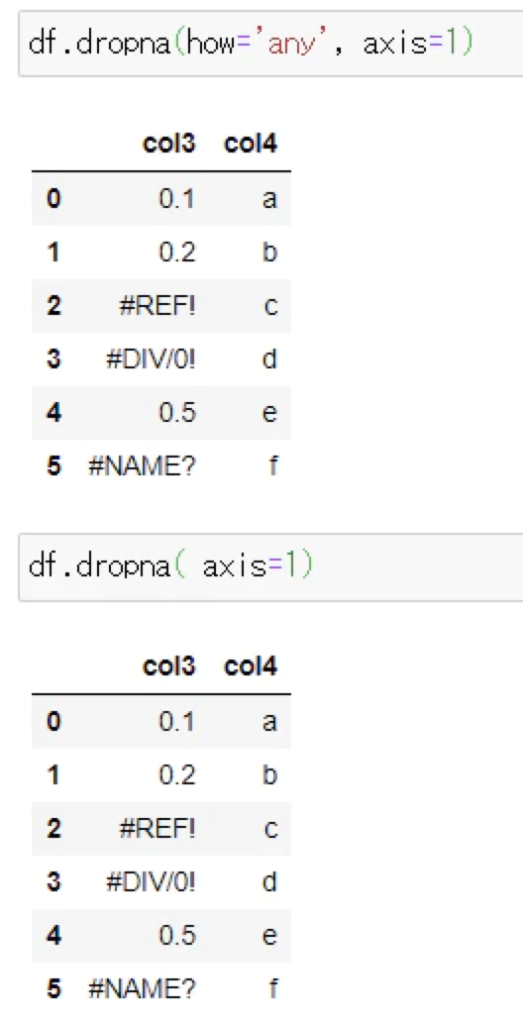
いずれも、NaNを一つ以上含む、col1, Unnamed:1, col5が削除されています。
欠損値でないセルの数を指定して削除する方法
欠損値NaNでない値がn個以上なら無視し、それ以下なら削除する処理ができます。
- 行の削除: df.dropna(thresh=n)
- 列の削除: df.dropna(thresh=n, axis=1)
▽補足
threshは「threshold(しきい値)」の略です。
元のデータ
次のようなDataFrameの表データで実行結果を紹介します。
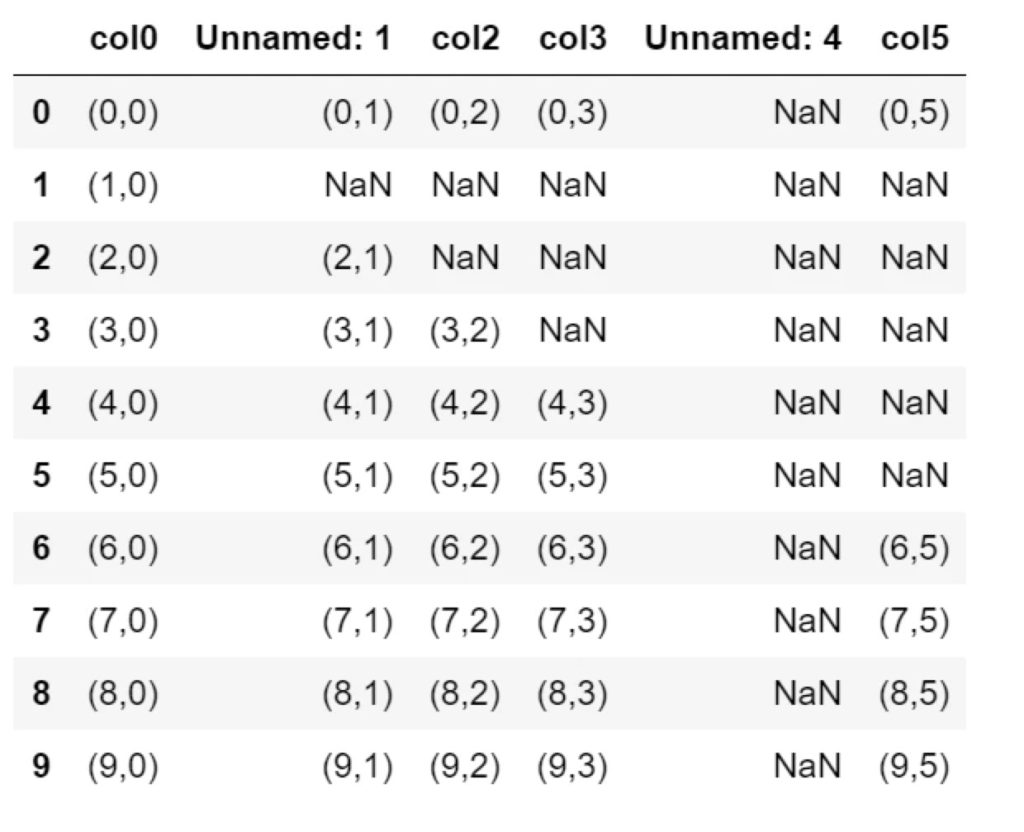
・10行×6列の表
・0行目はNaNの数が1(そうでないセルが9)。1列ずつNaNの数が増える。
・4列目はすべて空白
行の削除: df.dropna(thresh=n)
例:df.dropna(thresh=1)
└「df」:表データ
└「thresh=1」:しきい値1
NaN以外のセルが1つ以下の行を削除。
すべてNaNの行を削除と同じ。
▼thresh=1の場合
df.dropna(thresh=1)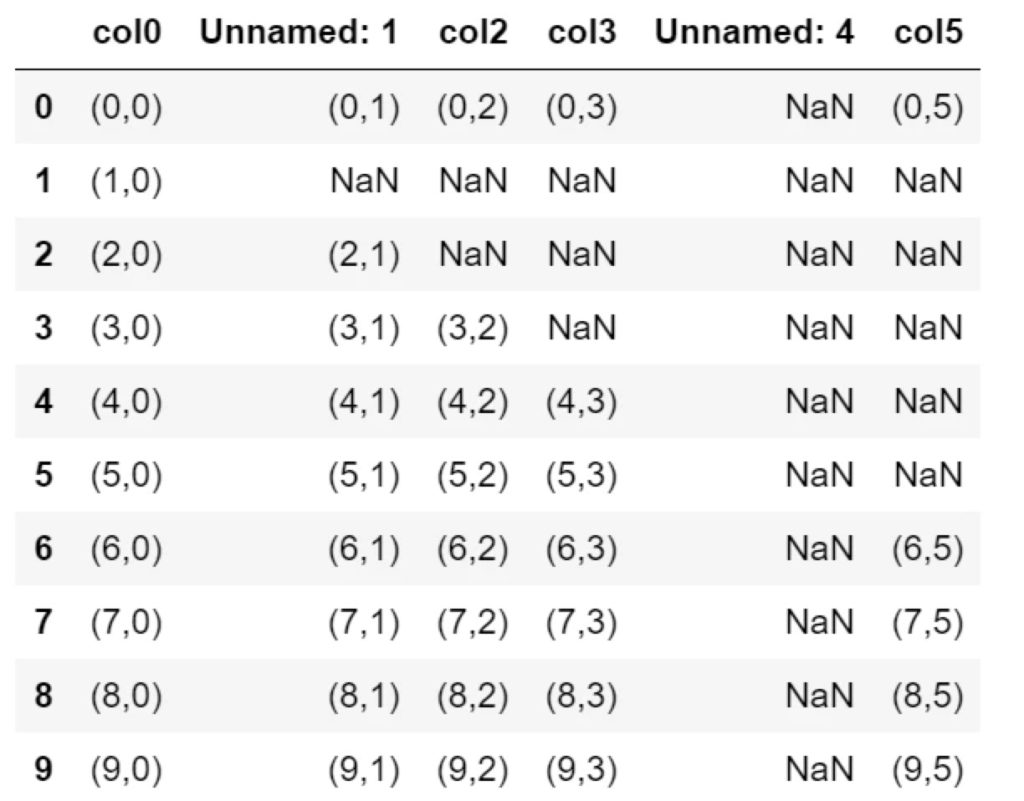
NaNのみのセルはないため、すべての行が残ります。
▼thresh=4の場合
df.dropna(thresh=4)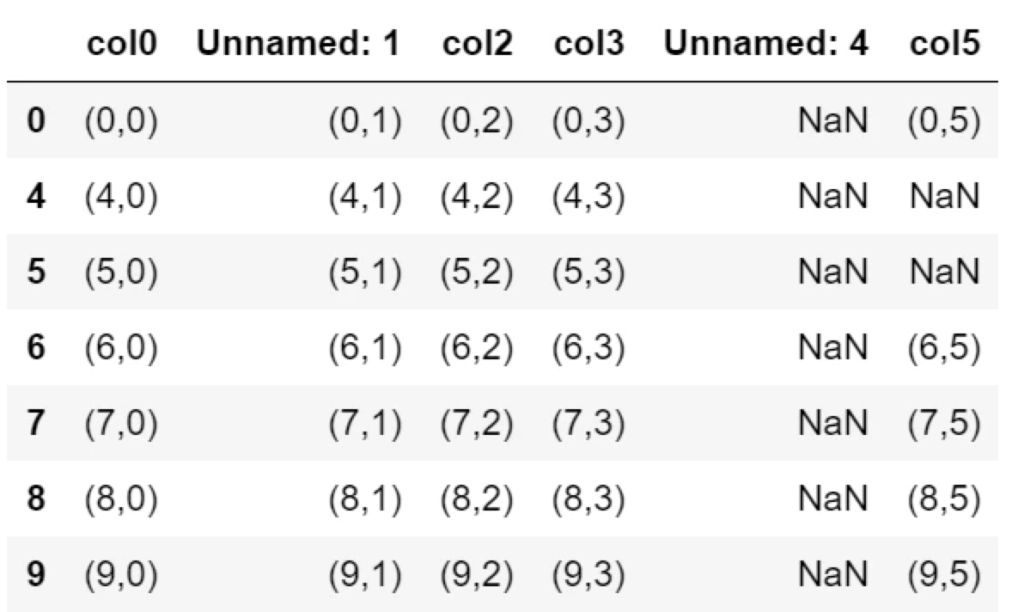
NaN以外のセルが4個以下の行、行1,2,3は削除されます。
▼thresh=7の場合
df.dropna(thresh=7)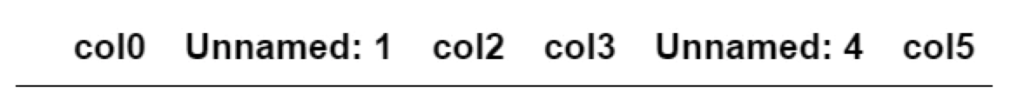
NaN以外のセルが7個以上の行はないため、すべて削除されます。
列の削除: df.dropna(thresh=n, axis=1)
例:df.dropna(thresh=1, axis=1)
└「df」:表データ
└「thresh=1」:しきい値1
NaN以外のセルが1つ以下の列を削除。
すべてNaNの列を削除と同じ。
▼thresh=1, axis=1の場合
df.dropna(thresh=1, axis=1)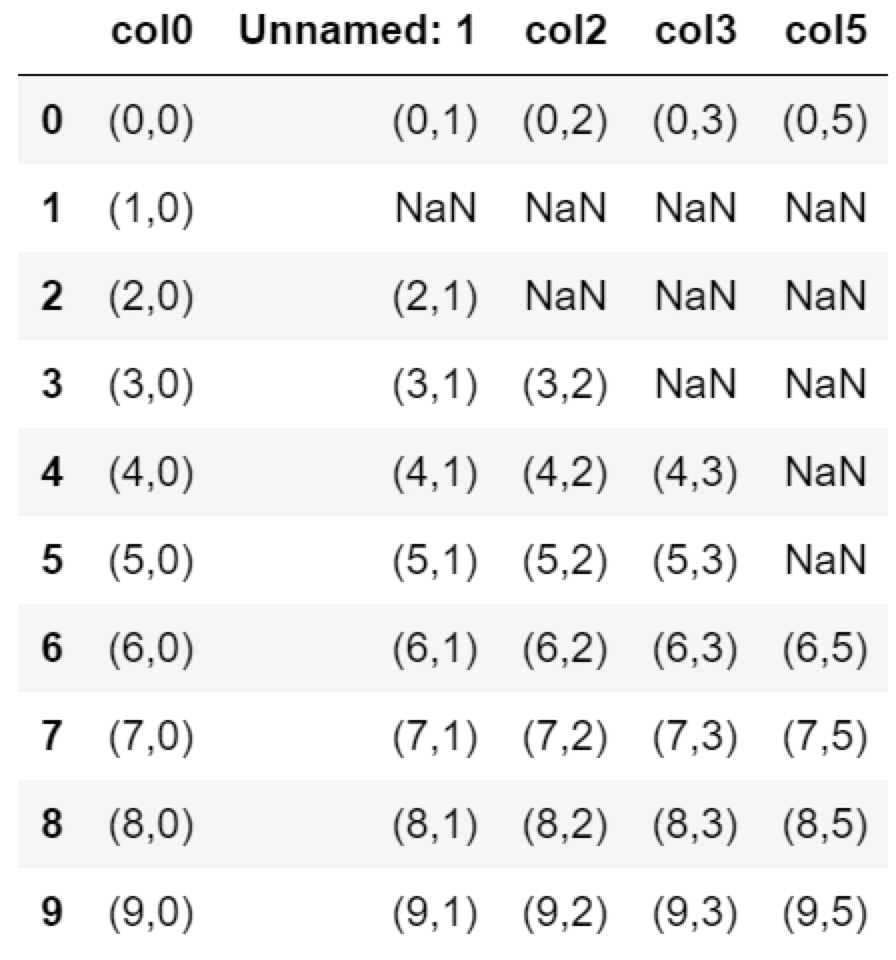
すべてNaNの列4が削除されます。
▼thresh=7, axis=1の場合
df.dropna(thresh=7, axis=1)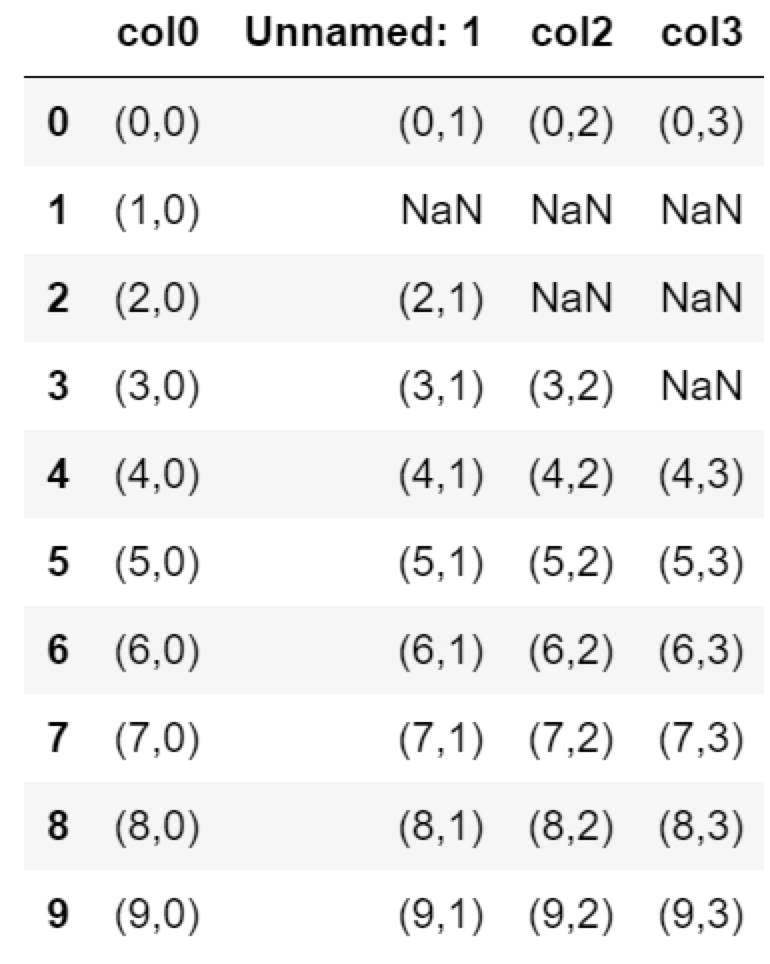
NaN以外のセルが7個以下の列、col4とcol5が削除されます。
▼thresh=11, axis=1の場合しきい値の指定(n=11)
df.dropna(thresh=11, axis=1)
NaN以外のセルが11個以上の列はないため、すべての列が削除されます。
指定した行・列の中の欠損値(NaN)を削除する方法
検索対象となる行や列を指定して、その中にあるNaNを削除するにはsubsetオプションを使用します。
- 行の中のNaNを削除: df.dropna(subset=[ ‘列名A’, ‘列名B’,,,, ])
- 列の中のNaNを削除: df.dropna(subset=[ ‘行名A’, ‘行名B’,,,, ], axis=1)
列を指定した場合は、指定した列のNaNが含まれている行を削除します。
行を指定した場合は、指定した列のNaNが含まれている列を削除します。
結果的に、指定した行や列にNaNがない状態となります。
- 行を削除したいときに、subsetで指定するのは列名になります(行名ではありません)
- 指定した列の中にNaNが存在する行をすべて削除します。
- 行を削除したい場合は、subsetで列名を指定。
- 列を削除したい場合は、subsetで行名を指定かつ、axis=1を追記。
元のデータ
次のようなDataFrameの表データで実行結果を紹介します。
・10行×6列
・行名はrow×行番号
・列名はcol×列番号
行の中のNaNを削除: df.dropna(subset=[ ‘列名A’, ‘列名B’,,,, ])
列名を指定して、その中のNaNが含まれる行を削除します。
df.dropna(subset=[ ‘列名A’, ‘列名B’,,,, ])
└「df」:表の入った変数
└「subset」:表または列の名前を指定するオプション
例:df.dropna(subset=[‘col1′,’col3′,’col5’])
列col1, col3, col5の中にNaNが一つでもある行を削除する。
⇛ 指定した列の中からNaNが消える。
df.dropna(subset=['col1','col3','col5'])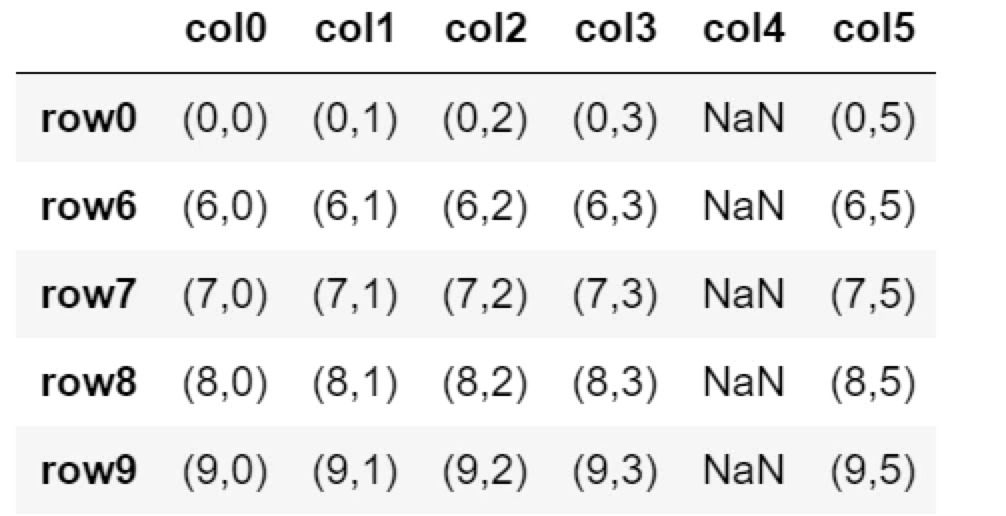
行1,2,3,4,5が削除。指定した列col1,3,5にNaNが含まれなくなりました。
列の中のNaNを削除: df.dropna(subset=[ ‘行名A’, ‘行名B’,,,, ], axis=1)
行名を指定して、その中のNaNが含まれる列を削除します。
例:df.dropna(subset=[‘row0′,’row3’], axis=1)
行row0, row3の中にNaNがある列を削除します(指定した列からNaNが消えます)。
df.dropna(subset=['row0','row3'], axis=1)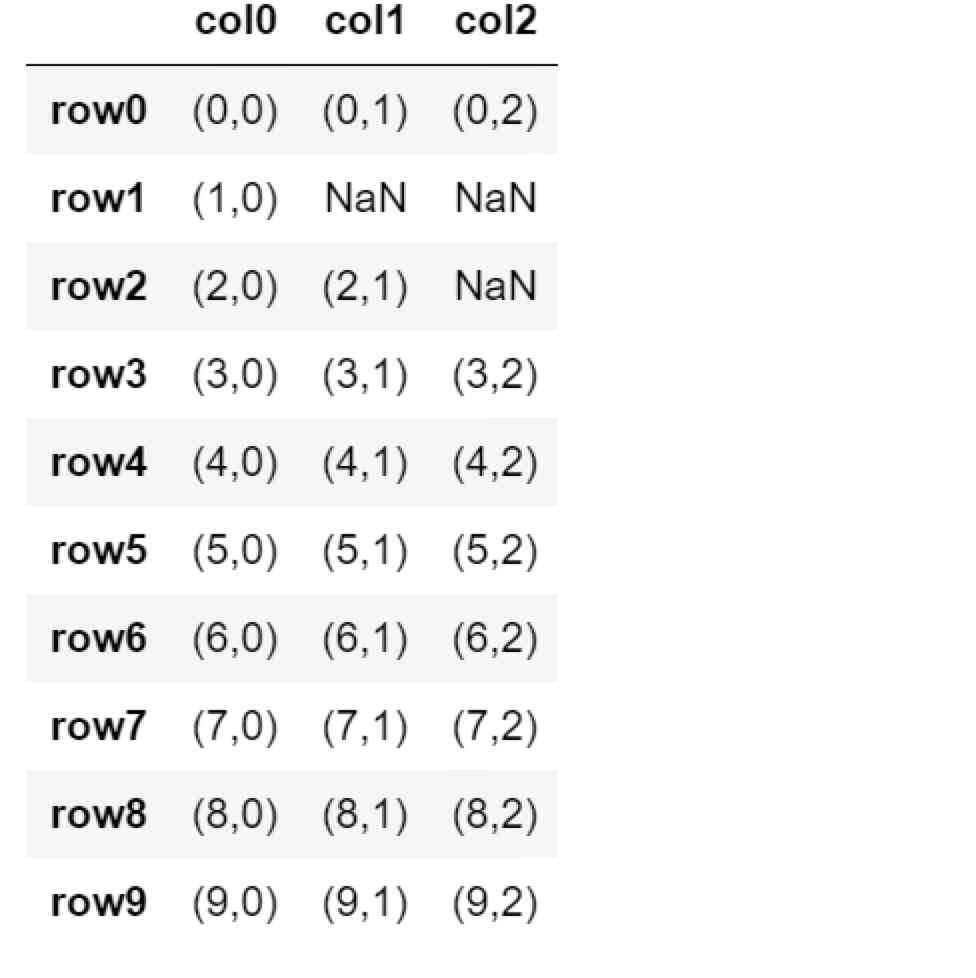
列col3, col4, col5を削除されました。
削除の上書きを許可する
dropnaメソッドはデフォルトは非破壊処理なので、元のデータはそのまま残ります。これを上書きするように設定するには inplaceオプションを使います。
デフォルトでは上書きしない設定です。
└inplace=False
上書きを許可するには下記を記述します。
└inplace=True
上書きを許可
df.dropna(thresh=5, inplace=True)
print( df )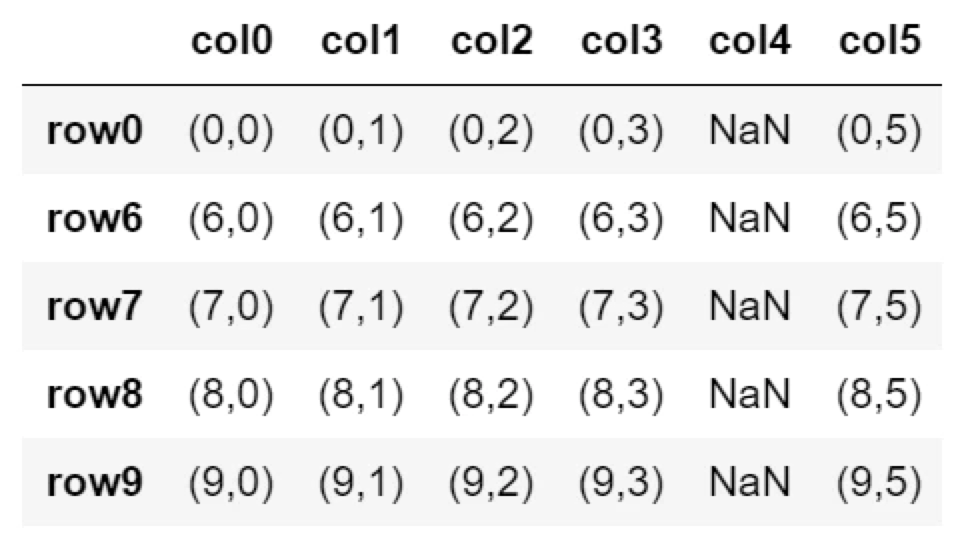
デフォルト(上書きしない)
df.dropna(thresh=5)
print( df )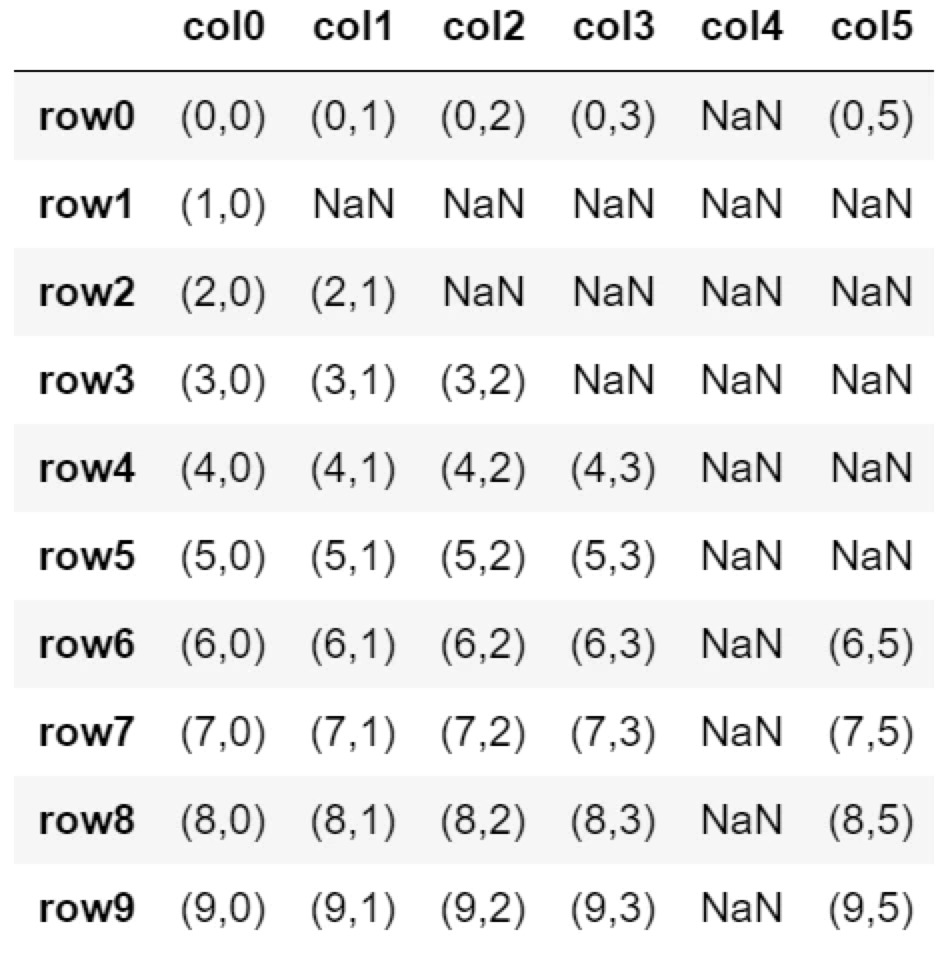
表は元のままです。
>公式ページ
dropnaメソッド
欠損値を変換(置換)する
fillnaメソッドでNaNを指定した値に置換することができます。
置換方法や置換対象とするNaNの条件はオプションで指定します。
fillnaメソッドのオプション一覧
| オプション | 内容 |
|---|---|
| axis=0 | 行(省略) |
| axis=1 | 列 |
| value | NaNを変換する値 |
| method=’bfill’ | NaNの下セルの値に変換 |
| method=’backfill’ | ‘bfill’と同じ |
| method=’ffill’ | NaNを上のセルの値に変換 |
| method=’pad’ | ‘ffill’と同じ |
| method=’bfill’, axis=1 | NaNの右セルの値に変換 |
| method=’ffill’, axis=1 | NaNの左セルの値に変換 |
| limit=n | n個目のNaNまで置換。それ以上は置換しない。 |
| inplace=True | 上書きを許可する |
①表全体のNaNを置換する方法
1-1. fillna(‘AAA’)
1-2. methodオプション
1-3. fillna(method=’ffill’)
1-4. fillna(method=’ffill’, axis=1)
1-5. fillna(method=’bfill’)
1-6. fillna(method=’bfill’, axis=1)
②何個目のNaNまで置換するか指定
1-1. fillna(‘AAA’, limit=n)
1-2. fillna(‘AAA’, limit=n, axis=1)
1-3. fillna(method=’ffill’, limit=n)
1-4. fillna(method=’ffill’, limit=n, axis=1)
③上書きを許可する
元のデータ
以下のDataFrameの表を使ってfillnaの実例を紹介します。
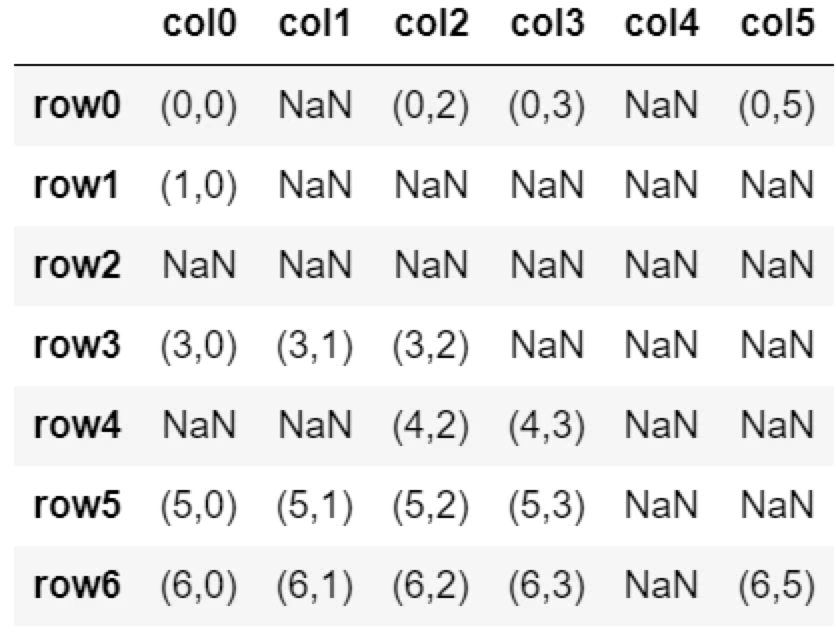
表全体のNaNを置換する方法
fillna(‘AAA’)
fillna('AAA')
└ 「AAA」:指定した文字でNaNを置換(任意)
df.fillna('AAA')
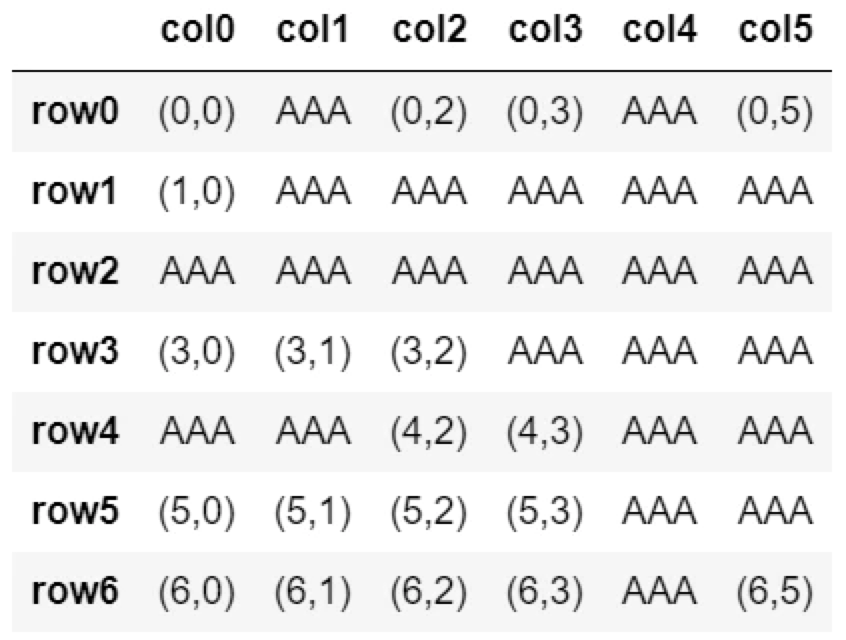
methodオプション
methodオプションを使用することでNaNに隣接する*値に置換できる。
*NaNが連続する場合は、値があるセルまで進む。
▼例:右のセルの値で置換するよう指定した場合
置換前:NaN NaN NaN AAA
置換後:AAA AAA AAA AAA
※値があるセルが存在しない場合はNaNとなる。
▼methodオプション一覧
| method | 意味 | 内容 |
|---|---|---|
| ffill | forward fill | 前方セルの値で置換(行:上側、列:左側) |
| pad | padding | ffillと同じ |
| bfill | backward fill | 後方セルの値で置換(行:下側、列:右側) |
| backfill | backward fill | bfillと同じ |
行指定の場合は、行番号ベースで前か後ろかを決める。(上か下になる)
列指定の場合は、列番号ベースで前か後ろかを決める。(左か右になる)
※methodオプションはvalueとは併用できない(エラーになる)エラー
ValueError: Cannot specify both 'value' and 'method'.
fillna(method=’ffill’)
fillna(method='ffill')
上の行の値で置換する。
df.fillna(method='ffill')
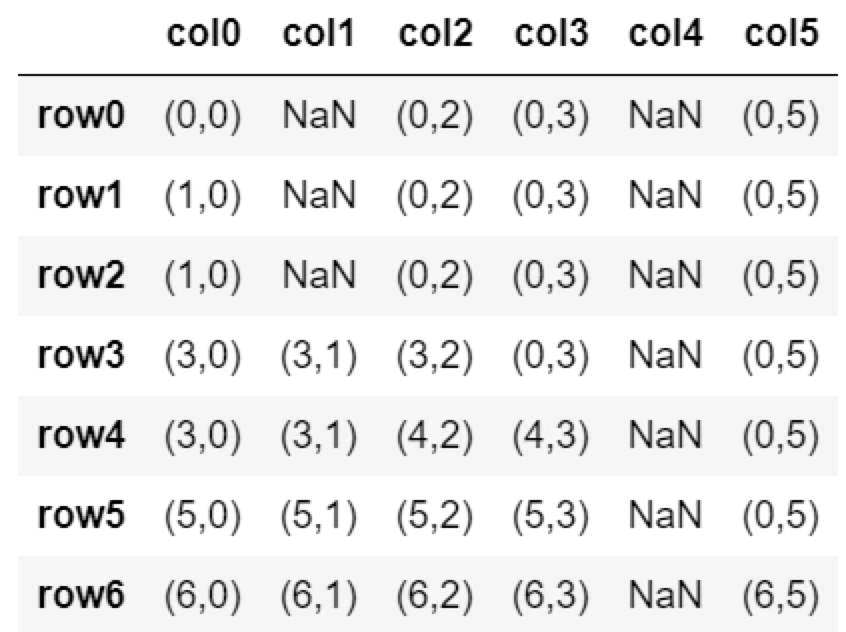
NaNの上にある値に変換する。
一番上の行がNaNの場合置換されない。
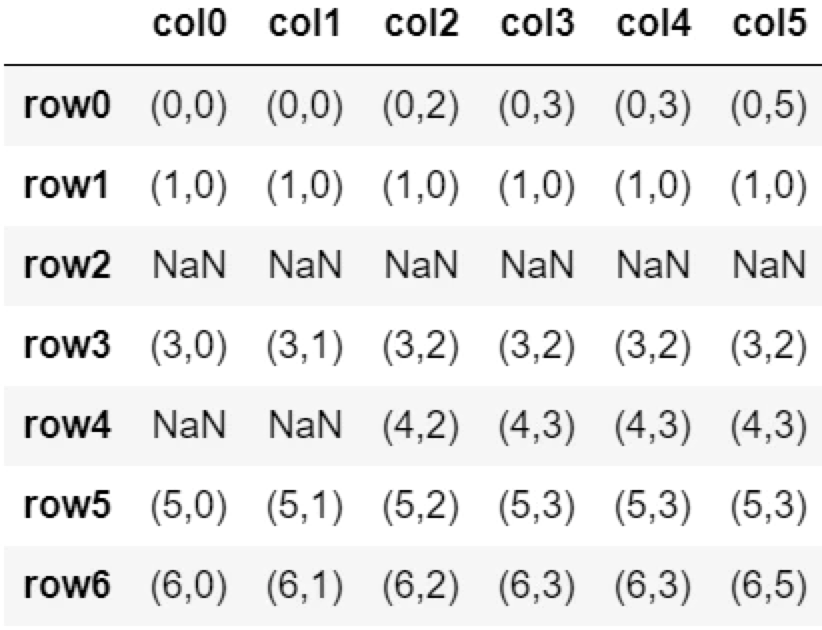
fillna(method=’ffill’, axis=1)
fillna(method='ffill', axis=1)
前方の列の値で置換する。
df.fillna(method='ffill', axis=1)
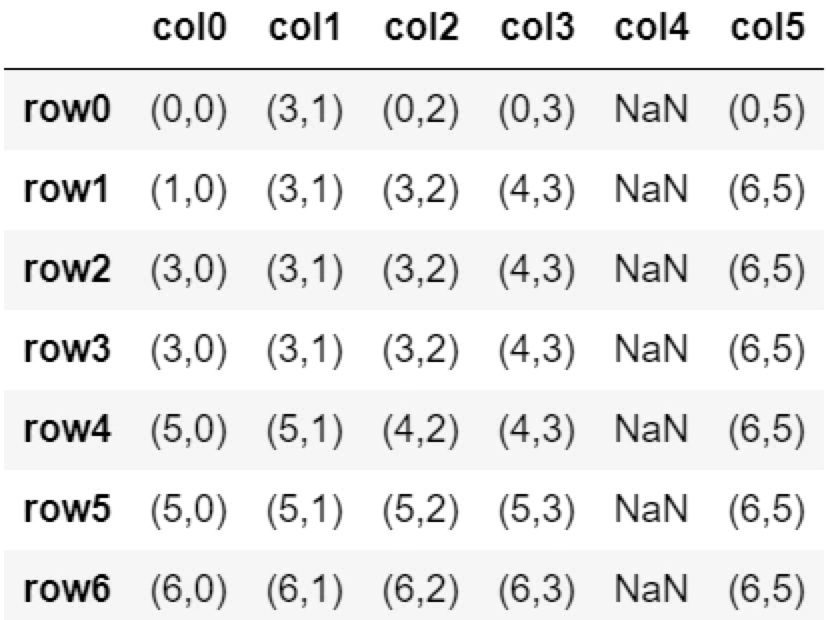
fillna(method=’bfill’)
fillna(method='bfill')
後方の行の値で置換する。
df.fillna(method='bfill')
fillna(method=’bfill’, axis=1)
fillna(method='bfill', axis=1)
後方の列の値で置換する。
df.fillna(method='bfill', axis=1)
何個目のNaNまで置換するかを指定する方法
limitオプションを使うことで、何個目のNaNまで置換するかを指定できる。
limit=n
n個目まで置換。それ以上は置換しない。
例: limit=2で、置換する値AAA、軸を列とした場合
■置換前
AAA NaN NaN AAA AAA
AAA NaN NaN NaN AAA
AAA NaN AAA NaN AAA
NaN NaN AAA NaN NaN
■置換後
AAA AAA AAA AAA AAA
AAA AAA AAA NaN AAA
AAA AAA AAA AAA AAA
AAA AAA AAA NaN NaN
・左から各行づつ、2つ目のNaNまで置換。
fillna(‘AAA’, limit=n)
fillna('AAA', limit=3)
行番号順で上から、NaNが2個目まで置換する。
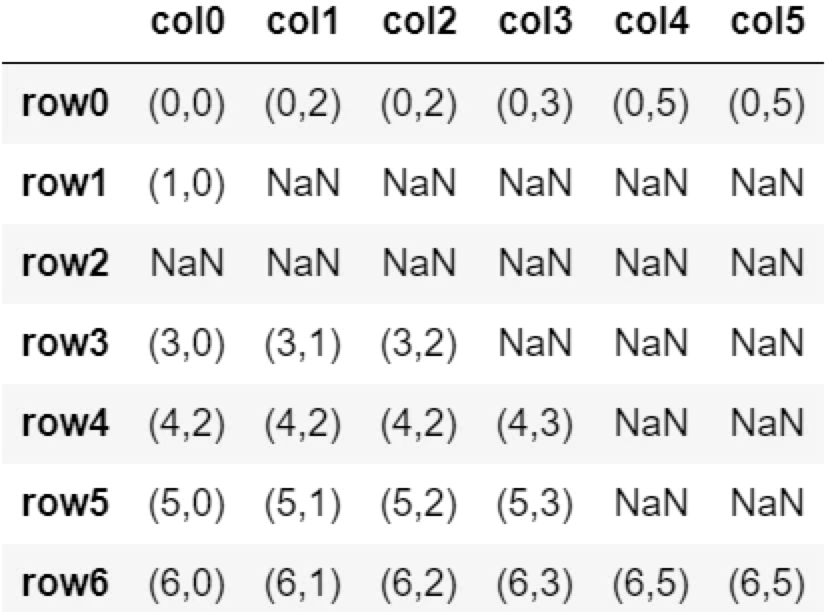
df.fillna('AAA', limit=2)
各列ごと上から2番目まで置換。それ以上は置換しない。
fillna(‘AAA’, limit=n, axis=1)
fillna('AAA', limit=3, axis=1)
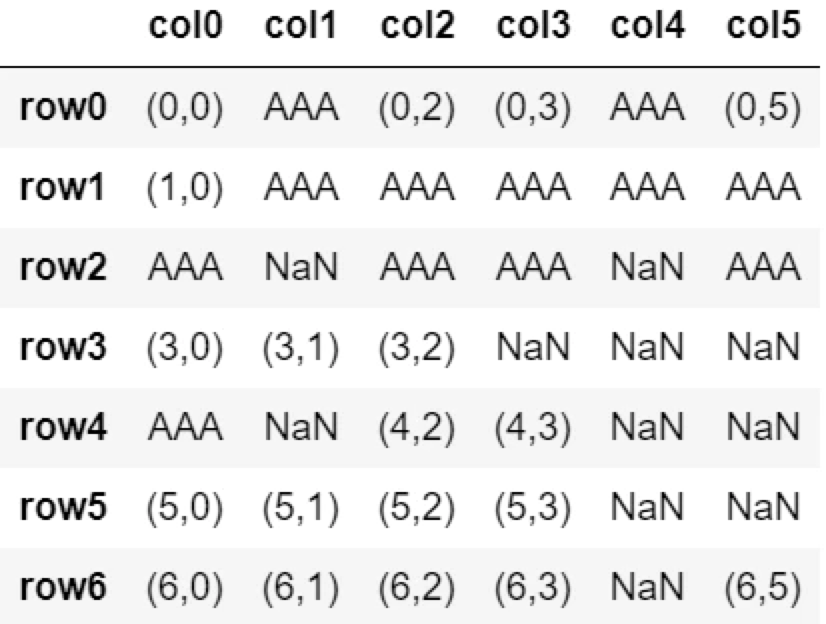
行番号順で上から、3個目のNaNまで置換する。
df.fillna('AAA', limit=3, axis=1)
fillna(method=’ffill’, limit=n)
fillna(method='ffill', limit=3)
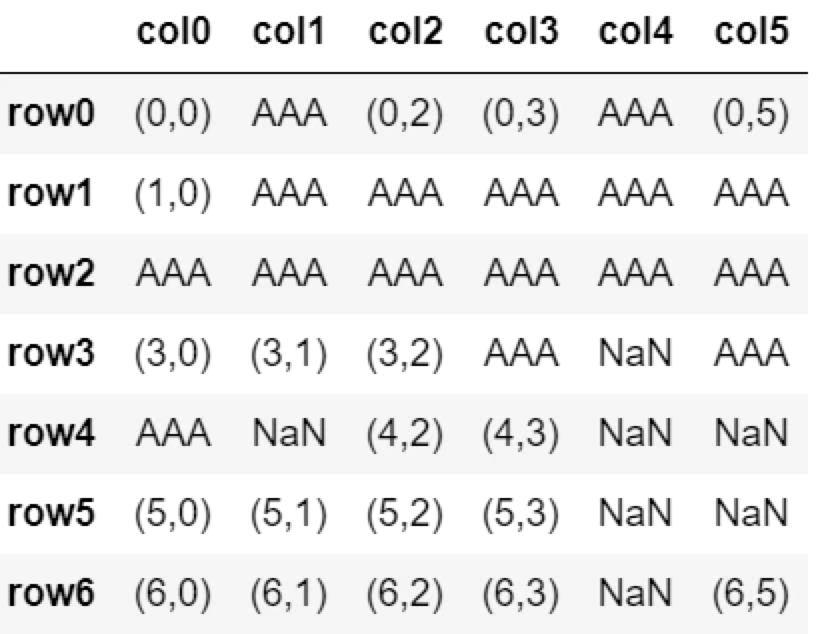
行番号順で3個目のNaNまでを前の値で置換する。
※先頭がNaNの場合は置換がされない(カウントされない)。最初の値のあるセルより後方から置換が開始する。
df.fillna(method='ffill', limit=3)
fillna(method=’ffill’, limit=n, axis=1)
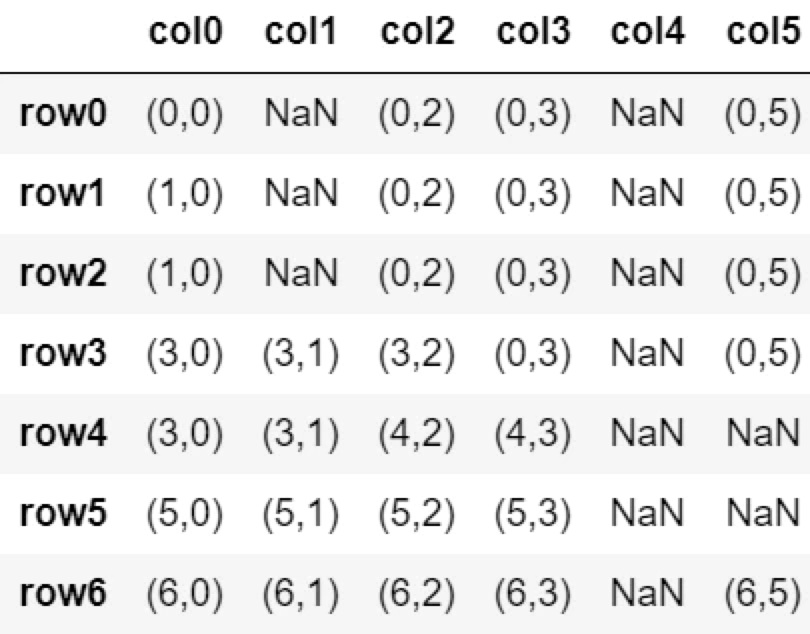
fillna(method='ffill', limit=3, axis=1)
列番号順で3個目のNaNまでを前の値で置換する。
※先頭がNaNの場合は置換がされない(カウントされない)。最初の値のあるセルより後方から置換が開始する。
df.fillna(method='ffill', limit=3)
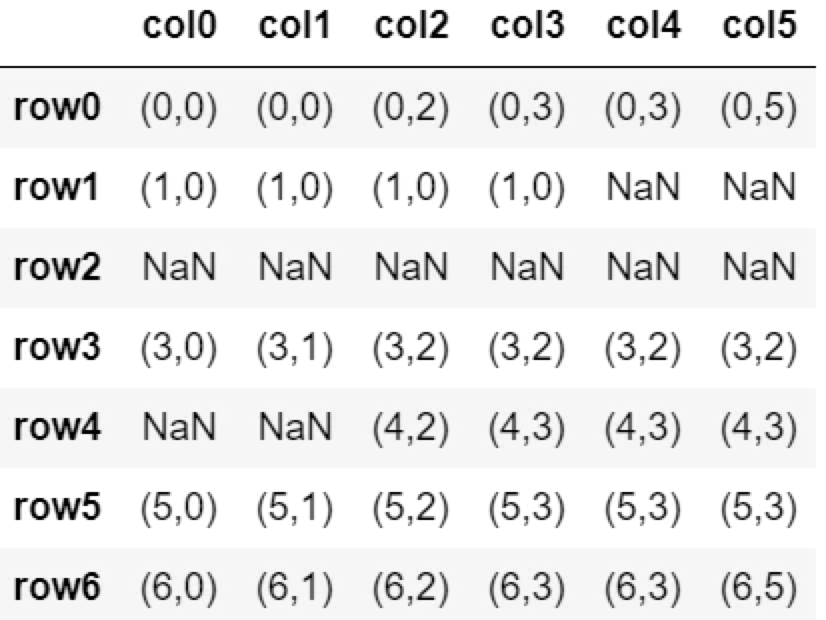
上書きを許可する
inplaceオプションを使用。
デフォルトでは上書きしない。
└inplace=False
上書きを許可するには下記を記述。
└inplace=True
▼上書きを許可
df.fillna('AAA', inplace=True)
df
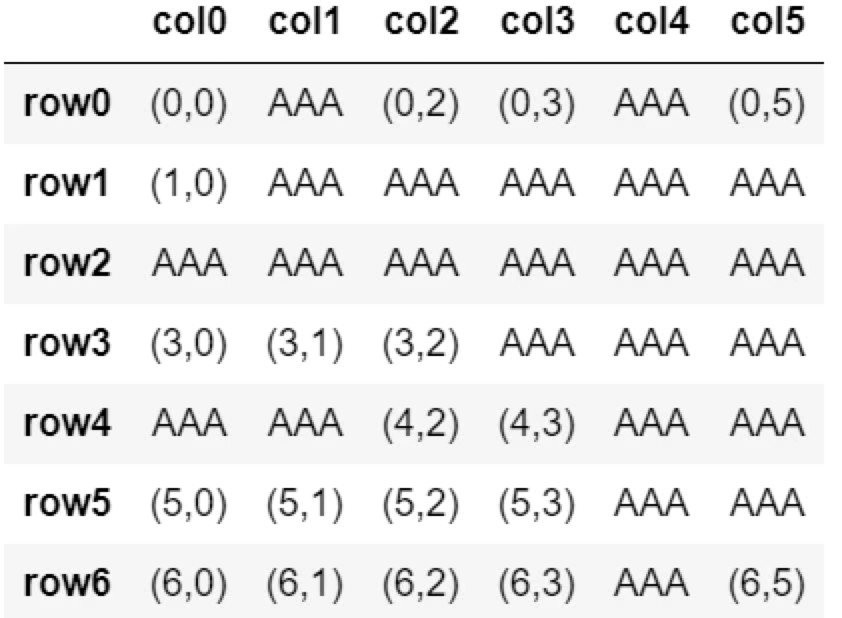
▼デフォルト(上書きしない)上書きなし
df.fillna('AAA')
df
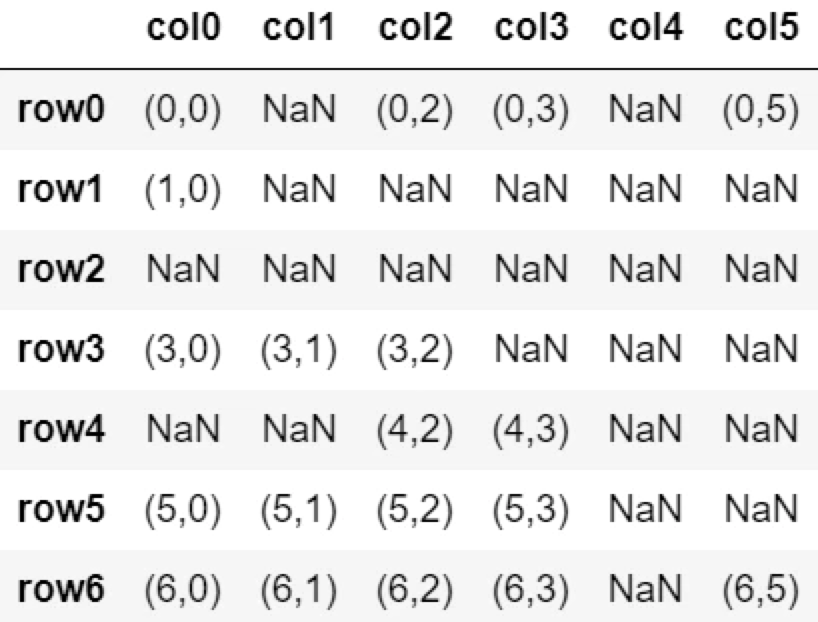
表は元のまま。
>公式ページ
dropnaメソッド

