

googleやbingのクローラーのアクセスを制御するrobots.txtがWordpressのディレクトリの中を検索しても見つからない、、
存在していないのかとおもいきや、実はwordpressが自動で生成してくれている。
そんなWordpressのrobots.txtの確認方法と実際にファイルとして作成する方法および、作成した場合の設置場所について。
WordPressのrobots.txtを確認する方法
WordPressのrobots.txtを確認は超簡単。URLでドメインの後に「robots.txt」と記述すれば確認できる。
https://example.com/robots.txt
たったこれだけ。するとブラウザ上にrobots.txtの中身が表示される。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/wp-sitemap.xml
Sitemap: https://example.com/sitemap.xml中の記述はrobots.txtの記述規則に沿っている。
robots.txtは本来プロジェクトのルートディレクトリ直下に配置するが、wordpressの場合はファイルが存在しない。
example.com/robots.txt というURLでアクセスがある度に、robots.txtを動的に作成する。その記述内容はWordpressの管理画面で設定した内容になる。
WordPressのrobots.txtの注意点
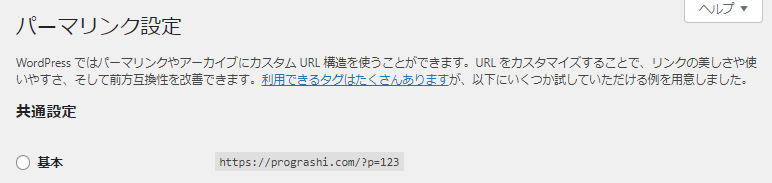
- パーマリンク設定がデフォルトの「基本」にチェックが入っているときは生成されない。(図1)
- ルート配下のディレクトリにインストールした場合、サイトアドレスの設定をルートにしないと生成されない(図2)
- 検索エンジンでの表示の「検索エンジンがサイトをインデックスしないようにする」にチェックを入れると、robots.txtに Disallow: / が記述される。(図3)
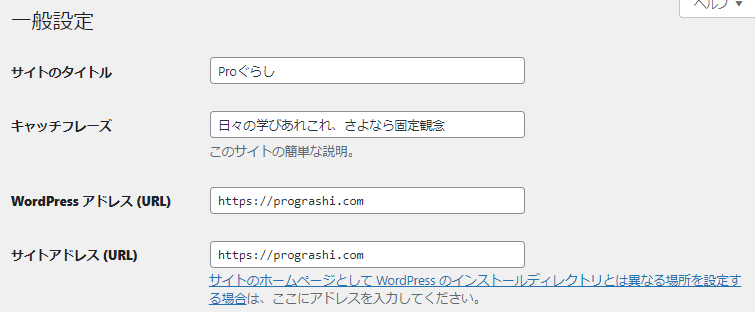
※wordpressのインストール先が、https://example.com/blog/ などの場合。サイトアドレスが https://example.com/blog/ のままだとrobots.txtは生成されない。

ここにチェックを入れるとrobots.txtは以下のようになる。
User-agent: *
Disallow: /「このリクエストを尊重するかどうかは検索エンジンの設定によります。」という記述があるが、これはrobots.txtの指示が完全ではないため。詳細は後述。
robots.txtの内容と記述方法
robots.txtは記述方法にルールがある。
User-agent: *
User-agentは記述した規則を適用するクローラーを指定する。主な指定方法は以下のとおり。冒頭大文字で記述しているが、小文字でも問題ない。
| 指定 | 内容 |
| * | すべてのクローラー |
| Googlebot | Googleクローラー |
| bingbot | Bingのクローラー |
| Googlebot-Image | 画像用 Googlebot |
| Googlebot-Video | 動画用 Googlebot |
| Googlebot-News | ニュース用 Googlebot |
| AdsBot-Google | 広告用Googlebot |
| AdsBot-Google-Mobile | モバイル用 広告用Googlebot |
User-agent: * はすべてのクローラーに対しての指示となる。Googleのクローラーは他にも種類がある。
(参考)Google公式 Google クローラの概要(ユーザー エージェント)
なお、User-agentで指定するクローラーは1行につき一つのみ。複数のクローラーに対する指示を書きたい場合は複数行記述する。
User-agent: bingbot
User-agent: AdsBot-Google
Disallow: /bingクローラーとGoogleの広告用クローラーにサイトをクローリングさせないようにする。
ちなみに、クローラーのことを、ボット(bot)とも呼ぶ。
Disallow: /wp-admin/
Disallow はクローラーのアクセスを拒否する指示になる。記述はURLのドメイン以下のパスを記述する。記述したディレクトリ配下がクローリング拒否の対象になる。
指定には正規表現も使用できる。大文字と小文字は区別される。
| 指定 | 対象 |
| / | すべてのページ |
| /wp-admin/ | /wp/admin配下 |
| /wp-admin/index.php | wp-admin配下のindex.phpのみ |
| /*.xls$ | 拡張子が.xlsのファイル |
正規表現の一例
「*」 は0回以上の繰り返し
「.」 は任意の1文字
「$」は末尾
つまり、/*.xls$ はホームディレクトリの後ろに任意の文字が1つ以上あり、xlsで終わるファイルが該当となる。
Disallow: /wp-admin/ は、wordpressのログインページが検索結果でひっかからないようにしている。
Allow: /wp-admin/admin-ajax.php
Allow: はDisallow: の逆でクローリングを許可するURIを指定する。
Disallowとセットで使うことで、DisallowしたURIの中の一部をクロールできるようにするために使う。
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phphttps://example.com/wp-admin/は配下はクローリングを拒絶するが、https://example.com/wp-admin/admin-ajax.phpは許可するという指示になる。
Sitemap: https://example.com/sitemap.xml
Sitemap: はサイトマップのURLを指定する。
一行に記述できるのは1つのURLのみ。複数のサイトマップを指定したい場合は別の行に記述する。サイトマップはワイルドカード「*」で指定することはできず、一つずつURLを指定する必要がある。
Sitemap: https://example.com/wp-sitemap.xml
Sitemap: https://example.com/sitemap.xmlsitemapが入れ子になっている場合、クローラーは内部のsitemapも辿るので、大元のsitemapのみ指定しておけば問題ない。
大文字と小文字の区別
大文字と小文字で区別される箇所と区別されない箇所がある。
具体的には、User-agent、Allowなどのプロパティは小文字でもいい。ただし、指定するパスは大文字と小文字を区別する。
例えば、Allow: /wp-admin/admin-ajax.php と、Allow: /wp-admin/Admin-Ajax.php は異なる。
グループ(一まとまりの処理ごとに改行する)
指示はグループ単位で行う。user-agentを指定して、その下にdisallowとallowの指示を記述する。
改行して1行あけると、その処理は終了となり、また次のグループでuser-agentを指定して処理を記述する。
user-agent: googlebot-news
disallow: /xxx
disallow: /yyy
user-agent: *
disallow: /zzz上記例の場合、2グループの記述となる。
News用のGoogleボットには /xxx、/yyy、/zzz をクローリングさせない。また、全てのクローラに /zzz をクローリングさせないという指示になる。
便利なrobots.txtの記述例
画像のクローリングを防ぐ
user-agent: googlebot-image
Disallow: /画像用のgooglebotがサイトのすべてのページにアクセスすることを拒否する。盗用防止など、画像検索で表示させたくないときに使う。
キャンペーン用のxlsとpdfへのアクセスを拒否する
user-agent: *
Disallow: /*.xls$
Disallow: /*.pdf$ダウンロードディレクトリ毎アクセスを拒否する
user-agent: *
Disallow: /download
Allow: /download/common.pdf
Allow: /download/common.indexこうすると、example.com/download 配下へのアクセスをすべて拒否できる。
その中でもインデックスを許可したいものがあれば、Allowで指定する。
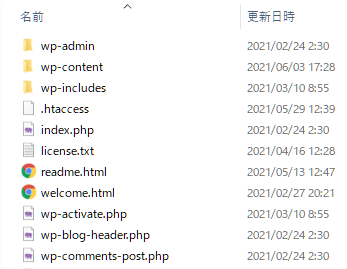
robots.txtの設置場所
robots.txtの設置場所はルートディレクトリ直下(.htaccessなどがあるところ)robots.txtは1つのみで、複数設置してはいけない。
また、ルートディレクトリ以外の場所に設置すると、クローラーがクローリングしない。
wordpressであればwp-admin, wp-contentなどがあるディレクトリと同じ階層に設置する。
robots.txtの注意点(disallowは完全ではない!)
SEO関連でよく見かける話題ですが、robots.txtでdisallowを設定しているのに、インデックスされてしまっている、、
ということが発生する。これは、robots.txtが完璧な指示ではないため。robots.txtは自分のサイトにアクセスしてきたクローラーの動きを制御することができるが、他のサイトからのリンクを辿ってくるクローラーの動きを制御することはできない。
このため、他のサイトに自分のサイトへのリンクがあれば、クローラーがそこを辿ってきてインデックスしてしまう。
インデックスを完全に防ぐ方法
インデックスを完全に防ぐには、そのhead内に以下タグを挿し込む。
<meta name='robots' content='noindex,nofollow' />noindexはページをインデックスさせないという強力な指示。
nofollowはページ内のリンクを辿ってはいけないというお願い。※お願いと書いたのは2020年以降Googleクローラーがnofollowを絶対的なルールではなくヒントとして活用する仕様に変更したため。

