

PythonのPandasのDataFrameで作成した表データの中で、重複する要素があるか調べる方法と、重複した値を削除する方法を実例を用いてまとめています。
excelで使う頻度の高い「重複の削除」と同等の処理をすることができます。
使用する表データ
実例用の元の表データとして以下のような6行5列の表を使っています。
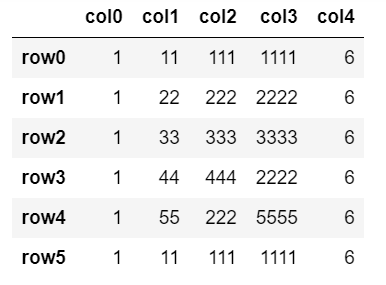
・row0とrow5が完全重複。
・col0, col4は要素がすべて重複
・col2はrow0=row5, row1=row4
・col3はrow0=row5, row1=row3
重複する行を確認する方法
・duplicatedメソッドを使用することで、重複要素がある行を抽出できる。
・重複した行がTrueとなる。
・デフォルトは上側の重複行をFalseとみなし、それ以下をTrueとみなす。
オプションで一番下側をTrueとすることも可能。
└ 削除するときに対象となるのが、上か下かを決める。
└ 重複行をすべて削除することも可能。
・対象となる列を列名で指定することも可能。
duplicatedメソッドの主なオプション
- duplicated()
- duplicated(keep=’last’)
- duplicated(keep=False)
- duplicated([‘列名’])
- duplicated([‘列名A’, ‘列名B’,,,,])
duplicated()
すべての列で完全に重複する行を重複判定する。重複した行のうち最初の行は重複でない(False)判定とし、以降の行を重複判定(True)にする。
duplicated()df.duplicated()
#出力
row0 False
row1 False
row2 False
row3 False
row4 False
row5 True
dtype: bool
row5だけが重複判定(True)となる。
すべての列で同一になるのはrow=0とrow=5。デフォルトは最初の行はFalseとするため、row5が重複判定となる。
▼(参考)元の表データ
なお、duplicatedメソッドのデフォルトのオプションは「keep=’first’」となっており、重複したうち上の行は残す設定になっている。
下記2つは同じ処理になる。
df.duplicated()
df.duplicated(keep=’first’)
duplicated(keep=’last’)
重複した最初の行を重複判定する。keep=lastで後ろ側を残すという意味。
duplicated(keep='last')df.duplicated(keep='last')
#出力
row0 True
row1 False
row2 False
row3 False
row4 False
row5 False
dtype: bool
row0が重複判定(True)となる。
▼(参考)元の表データ
duplicated(keep=False)
重複した行はすべて重複判定する。keep=False
※Falseは文字列ではないのでクオテーションは不要。
duplicated(keep=False)df.duplicated(keep=False)
#出力
row0 True
row1 False
row2 False
row3 False
row4 False
row5 True
dtype: boolrow0とrow5が重複判定(True)となる。
▼(参考)元の表データ
duplicated([‘列名’])
指定した列のみ重複判定を行う。デフォルトの keep=’first’ になっているため、一番最初のみ重複判定にならない(Falseになる)
df.duplicated(['列名'])keepオプションと併用可能。
▼duplicated([‘col0’])の場合
df.duplicated(['col0'])
#出力
row0 False
row1 True
row2 True
row3 True
row4 True
row5 True
dtype: bool
col0の要素はすべて1のため、1列目を除きすべて重複判定となる。
▼(参考)元の表データ
duplicated([‘列名A’, ‘列名B’,,,,])
重複判定する列を複数指定する。
※指定した各行がいずれも重複判定(True)のときのみ、Trueを返す。
※1列でも異なる場合はFalseになる。
duplicated(['列名A', '列名B',,,,])keepオプションと併用可能。
▼duplicated([‘col0′,’col3’])の場合
df.duplicated(['col0','col3'])
#出力
row0 False
row1 False
row2 False
row3 True
row4 False
row5 True
dtype: boolrow3とrow5のみTrueとなる。
└col0とcol3のrow3がTrue → True
└col0とcol3のrow5がTrue → True
└col0とrow1はTrue, col3のrow1はFalse → False
▼(参考)元の表データ
重複する行を削除する方法
drop_duplicatesメソッドを使う。重複の確認と違い複数形
duplicatedメソッドで重複判定(True)となった行が削除対象となる。
- 削除は複数形: drop_duplicates
- 確認は単数形: duplicated
drop_duplicatesメソッドの主なオプション
- drop_duplicates
- drop_duplicates(keep=’last’)
- drop_duplicates(keep=False)
- drop_duplicates([ ‘行名’ ])
- drop_duplicates([ ‘行名A’, ‘行名B’,,,, ])
drop_duplicates
drop_duplicates()はすべての要素が重複している行を削除する。
その際、一番上の行は残す(keep=’first’)drop_duplicates
df.drop_duplicates()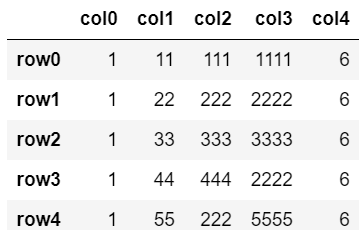
row5が削除された。
row0とrow5が重複。一番上の行は重複判定されないため(デフォルトkeep=’first’)、row5が削除対象となった。
▼(参考)元の表データ
drop_duplicates(keep=’last’)
drop_duplicates(keep=’last’)はすべての要素が重複している行を削除する。
その際、一番下の行は残す(keep=’last’)keep=’last’
df.drop_duplicates(keep='last')

重複した一番最初の行 row0 が削除された。
▼(参考)元の表データ
drop_duplicates(keep=False)
重複している行をすべて削除する。keep=Falseで残さないという意味。
df.drop_duplicates(keep=False)
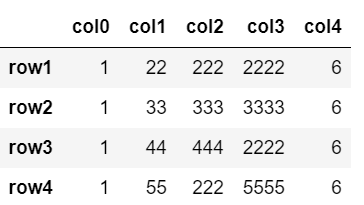
row0, row5どちらも削除。
▼(参考)元の表データ
drop_duplicates([‘行名’])
指定した列の中で重複する行を削除。
drop_duplicates(['行名'])
drop_duplicates([‘col0’])の場合
df.drop_duplicates(['col0'])
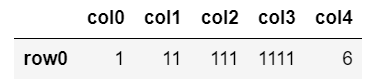
col0はrow0~row5まですべての要素が重複。
row1以外重複判定となるため削除対象となる。
drop_duplicates([‘col0′], keep=’last’)の場合
drop_duplicates(['col0'], keep='last')

keep=’last’にすると一番下の行が重複判定ではなくなる。
▼(参考)元の表データ
drop_duplicates([ ‘行名A’, ‘行名B’,,,, ])
指定した複数列の中で重複する行を削除。
drop_duplicates([ '行名A', '行名B',,,, ])df.drop_duplicates([‘col2’, ‘col3’])の場合複数列を指定
df.drop_duplicates(['col2', 'col3'])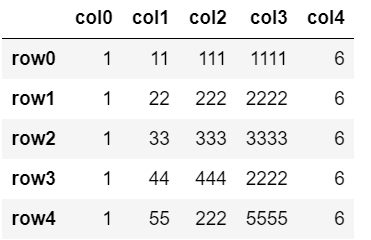
row5が削除。
col2で重複しているのは、row1, row4, row5。
col3で重複しているのは、row1, row5。
⇛ 共通はrow1とrow5。最初の重複行は残す設定(デフォルト keep=’first’)のため、row5のみ削除となる。
▼(参考)元の表データ
重複する行名を確認&削除する方法
オブジェクトに行を指定すれば、同じ名前の行がないか確認したり、重複を除外した行名の一覧を表示できる。
①重複する行名の確認 :df.index.duplicated()
②重複する行名を削除して確認 :df.index.drop_duplicates()
keep=’first’
└ 重複のうち最初の行名は重複判定しない
keep=’last’
└ 重複のうち最後の行名は重複判定しない
keep=False
└ 重複する行名はすべて重複とみなす
└ Falseの場合はクオテーション不要
重複する行名の確認
df.index.duplicated()- 「df」:表のデータ
- 「.index」:行名一覧の取得
- 「.duplicated()」:重複する行をTrueで表示
「.duplicated()」のオプションはデフォルト「keep=’first’」のため1つ目の重複する行はFalse、2つ目以降がTrueとなる。
df.index.duplicated()
#出力
# array([False, False, False, False, True, True])▼(参考)元の表データ
0番目と5番目、1番目と4番目の行名が重複。
⇛ 5番目と4番目が重複判定。
keep=Falseの場合
重複する行名はすべて重複(True)とみなす。
df.index.duplicated(keep=False)
#出力
# array([ True, True, False, False, True, True])重複する行名を削除して確認
df.index.drop_duplicates()重複した行名を削除して、行名のlistを取得する方法。
行名の確認をしたい場合などに利用。行名を削除して取得
df.index.drop_duplicates()
#出力
# Index(['AAA', 'BBB', 'CCC', 'DDD'], dtype='object')重複していた2つ目の「AAA」「BBB」は削除されている。
▼(参考)元の表データ
重複する列名を確認&削除する方法
行ではなく列で重複の確認や削除をしたい場合は、メソッドの前のオブジェクトに列名の入ったデータを指定すれば、列名で同様の処理ができる。
上記の、.index を .columns に変更すればOK。
①重複する列名の確認 :df.columns.duplicated()
②重複する列名を削除して確認 :df.columns.drop_duplicates()
columnsメソッドは表の列名をlistで抽出する。
参考リンク
Pandas公式ページ
・duplicated
・drop_duplicates

