

PandasのDataFrameの表データの要素を削除する方法のまとめです。dropメソッドのオプションについて実際の使い方を実例で解説しています。
異なる記述で同じ処理がありどれを使ったらいいか迷う場合もありますが、基本的には「columns=label」と「index=label」の2つのオプションをを覚えておけば行列の削除は可能です。
また、dropメソッドは非破壊処理のため、元のデータを変更せず、コピーして新しいオブジェクトを作成しますが、オプションを設定することで元のデータを変更する設定にすることができます。
dropメソッド・オプション一覧早見表
| オプション | 記述例 | 内容 |
|---|---|---|
| (columns=label) | df.drop(columns=[‘x’, ‘y’]) | 列x,yを削除 |
| (index=label) | df.drop(index=[‘A’, ‘B’] | 行A,Bを削除 |
| (labe) | df.drop([‘A’, ‘B’]) | 行A,Bを削除 |
| (label, axis=’index’) | df.drop([‘A’, ‘B’], axis=’index’) | 行A,Bを削除 |
| (label, axis=1) | df.drop([‘x’, ‘y’], axis=1) | 列x,yを削除 |
| (label, axis=’columns’) | df.drop([‘x’, ‘y’], axis=’columns’) | 列x,yを削除 |
| (errors=’ignore’) | df.drop([‘aaa’], axis=’columns’, errors=’ignore’) | エラーを無視 |
| (inplace=True) | df.drop([‘A’, ‘B’], inplace=True) | 上書きする |
- 「df」:表データの入った変数(変数名は実行環境に合わせてください)
- 「label」:行または列の名前
- デフォルトは上書きせず別のオブジェクトを作成
- 「index=」と「columns=」または「axis=1」のどちらか一方で行列の指定が可能。
使用する表データ
行や列を削除する方法を解説するために、以下の4行4列かつ、行列見出しがついた表を使用しています。
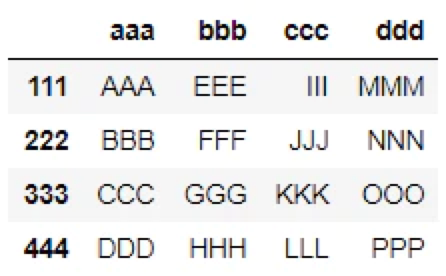
import pandas as pd
listA = ['AAA', 'BBB', 'CCC', 'DDD']
listB = ['EEE', 'FFF', 'GGG', 'HHH']
listC = ['III', 'JJJ', 'KKK', 'LLL']
listD = ['MMM', 'NNN', 'OOO', 'PPP']
lists = [listA, listB, listC, listD]
df = pd.DataFrame(lists)
df.columns = ['aaa', 'bbb', 'ccc', 'ddd']
df.index = [111,222,333,444]
print( df )
#出力
aaa bbb ccc ddd
111 AAA BBB CCC DDD
222 EEE FFF GGG HHH
333 III JJJ KKK LLL
444 MMM NNN OOO PPP表の作成方法や行名や列名を変更する方法は以下をご参考ください。
dropメソッドの主要オプション
PandasのDataFrameオブジェクトの表を削除するには、dropメソッドを使います。行・列の削除には以下の3つのオプションを使います。
- drop(label, axis)
- drop(index=label)
- drop(columns=label)
labelのところに行や列の名前を記述します。axisは軸という意味で、行か列どちらが削除対象なのかを指定します。
indexは行、columnsは列になります。
なお、dropメソッドは非破壊処理なので、元の表はそのまま残ります。dropメソッドを使う際は、処理後のデータを変数に格納する必要があります。
drop(label, axis)の使い方
labelで行や列の名前を指定し、axisで対象が列か行どちらになるかを指定します。
基本の型
df.drop(label, axis=値)- 「df」:表データ(DataFrame型)
- 「drop()」:ドロップメソッド
- 「label」:削除する行/列名
- 「axis=値」:行か列の指定
▼ポイント
– axisで行、列どちらかを指定。
– axsiの指定方法は4パターンある。
– 元の表はそのままで、新しいDataFrameオブジェクトが生成される。
– 間違って消しても復元できる
▼4つのaxisの指定方法
削除対象が行か列どちらになるかを指定するaxisには、指定方法が複数あります。デフォルトの指定は行になっています。
| 値 | 記述例 | 内容 |
|---|---|---|
| 0 | axis=0 | 行。デフォルト。省略可 |
| 1 | axis=1 | 列 |
| index | axis=’index’ | 行 |
| columns | axis=’columns’ | 列 |
行を削除する方法
行を削除するためのaxisの指定には、下記2つ(省略も含めると3つ)の記述が可能です。
dropのデフォルト設定が行になっているので、特に記述する必要はありません。
①axis=0(省略可)
②axis=’index’
axis=0は省略しても同様の処理になります。以下の処理は同じです。
df.drop([label1,label2,,,], axis=0)
df.drop([label1,label2,,,])
例: 1列のみ指定する場合
df.drop(333)
#出力
aaa bbb ccc ddd
111 AAA EEE III MMM
222 BBB FFF JJJ NNN
444 DDD HHH LLL PPP
df.drop(333, axis=0)
#出力
aaa bbb ccc ddd
111 AAA EEE III MMM
222 BBB FFF JJJ NNN
444 DDD HHH LLL PPP
例: 複数の列を指定する場合
df.drop([111,333])
#出力
aaa bbb ccc ddd
222 BBB FFF JJJ NNN
444 DDD HHH LLL PPP
axis=’index’で指定する場合
「axis=’index’」を指定しても、axis=0(省略)と同じになります。
df.drop([label1,label2,,,], axis=’index’)
df.drop([111,333], axis='index')
#出力
aaa bbb ccc ddd
222 BBB FFF JJJ NNN
444 DDD HHH LLL PPP
列を削除する方法
drop(label, axis)を使って列を削除する場合、axisは2つの書き方ができます。(どちらも同じ処理になります。)
- axis=1
- axis=’columns’
axis=1で指定する方法
df.drop([label1,label2,,,], axis=1)
└ axis=1の「1」が対象が列であることを指します。
▼1列のみ指定
1列の場合[ ]がなくても同じ処理になります。
df.drop(['AAA'], axis=1)df.drop('AAA', axis=1)(axis=1)
df.drop('bbb', axis=1)
#出力
aaa ccc ddd
111 AAA III MMM
222 BBB JJJ NNN
333 CCC KKK OOO
444 DDD LLL PPP
▼複数列指定列名の複数指定
df.drop(['bbb','ddd'], axis=1)
#出力
aaa ccc
111 AAA III
222 BBB JJJ
333 CCC KKK
444 DDD LLL
axis=’columns’で指定する方法
「axis=’columns’」を指定しても、axis=1と同じ処理になります。
df.drop([label1,label2,,,], axis=’columns’)
df.drop(['bbb','ddd'], axis='columns')
#出力
aaa ccc
111 AAA III
222 BBB JJJ
333 CCC KKK
444 DDD LLL
drop(index=label)
drop(index=label)を使うと、行名を指定して削除することができます。labelの部分に削除したい行の名前を記述します。
複数ある場合は、配列で指定します。
df.drop(index=label)
└ 「label」に削除したい行名を記述
df.drop(index=[222,444])
#出力
aaa bbb ccc ddd
111 AAA EEE III MMM
333 CCC GGG KKK OOO
なお、この処理は以下の3つと同じ処理になります。
df.drop(label)df.drop(label, axis=0)df.drop(label, axis='index')
drop(columns=label)
drop(columns=label)を使うと、列名を指定して削除することができます。labelの部分に削除したい列の名前を記述します。
複数ある場合は、配列で指定します。
df.drop(columns=label)
└ 「label」:削除したい列名を記述index=label
df.drop(columns=['ddd','bbb'])
#出力
aaa ccc
111 AAA III
222 BBB JJJ
333 CCC KKK
444 DDD LLL
なお、この処理は以下の3つと同じ処理になります。
df.drop(label, axis=1)df.drop(label, axis='columns')
dropメソッドのその他オプション
dropメソッドには、行と列の削除を実行するときに使える追加のオプションが用意されています。
上書きを許可する方法(破壊処理にする)
dropメソッドは、デフォルトでは元の表を変更せず、新しいオブジェクトを生成する非破壊の処理です。
オプションに inplace=True を指定することで、元のオブジェクトをそのまま変更する破壊処理にすることができます。
inplace=True
└ デフォルトは「False」
df.drop(columns=['ddd','bbb'], inplace=True)
df
#出力
aaa ccc
111 AAA III
222 BBB JJJ
333 CCC KKK
444 DDD LLL
元の表(df)が書き変わっていることがわかります。
エラーを表示しない
オプションでerrors=’ignore’を設定すると、エラーが発生しても無視する設定にできます。
デフォルトは「errors=’raise’」で、エラーを報告(raise)する設定になっています
errors=’ignore’オプションの使用例
存在しない列を削除すると本来エラーが発生しますが、errors=’ignore’ があれば何も表示されません。
df.drop(columns=['xxx'], errors='ignore')なお、「errors=’ignore’」の記述がない場合は以下のようなエラーが表示されます。
「KeyError: “[‘xxx’] not found in axis”」

