

PythonのDataFrameで作成した表を行または列で昇順や降順でソートする方法や、ソート時の欠損値NaNの動き(一番上か一番下のどちらに移動するか)を指定する方法を実例でパターン別に解説しています。
表のソートにはDataFrameのsort_valuesメソッドを使います。sort_valuesの処理はデフォルトは非破壊のため、元の表は変更されずにそのまま残りますが、オプションの指定で上書きするように変更することもできます。
sort_valuesメソッドの基本構文
sort_valuesメソッドの基本構文
sort_valuesメソッドは以下のように指定します。
df.sort_values(by=[‘A’])
└「df」:表データ
└「by=[]」:ソートの基準となる列/行※必須※
└「A」:列/行名
sort_valuesメソッドの主要オプション
降順や昇順、また行か列どちらに対してソートを実行するかはオプションで指定します。
▼主要オプション一覧
| オプション | 内容 |
|---|---|
| axis=0 | 軸を列とする。デフォルト。省略可 |
| axis=1 | 軸を行にする。 |
| by=[‘A’] | 軸とする行/列名。必須 |
| assending=True | 昇順ソート。デフォルト。省略可 |
| assending=False | 降順ソート。 |
| na_position=’first’ | NaNを最上部に移動。 |
| na_position=’last’ | NaNを最下部に移動。デフォルト。省略可 |
| inplace=False | 上書きしない。デフォルト。省略可 |
| inplace=True | 上書きする。 |
使用する表
sort_valuesメソッドの処理内容を紹介するにあたり、以下のような6行5列の表を使います。NaNは欠損値です。
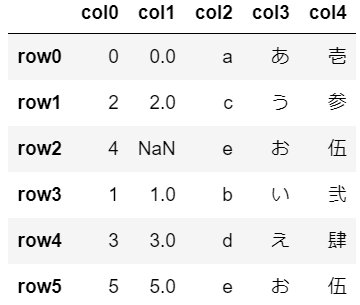
import pandas as pd
import numpy as np
row0 = [0, 0, 'a', 'あ', '壱']
row1 = [2, 2, 'c', 'う', '参']
row2 = [4, np.nan,'e', 'お', '伍']
row3 = [1, 1,'b', 'い', '弐']
row4 = [3, 3,'d', 'え', '肆']
row5 = [5, 5,'e', 'お', '伍']
df = pd.DataFrame([row0,row1,row2,row3,row4,row5])
df.columns = ['col0', 'col1', 'col2' ,'col3', 'col4']
df.index = ['row0', 'row1', 'row2', 'row3', 'row4', 'row5']
df欠損値NaNを使用するために、numpyをimportし「np.nan」を使用。
列を指定してソートする方法
列を指定してソートする方法として以下の4つのパターンを紹介します。
- 昇順ソート
- 降順ソート
- 欠損値(NaN)を含む列のソート
- 元の表を上書きする
指定した列の要素を元に行を並べ替える処理になります。
昇順ソート
df.sort_values(by=[‘列名’])
byオプションでソート基準となる列名を指定します。
デフォルトの設定が「ascending=Ture」なので、以下の2つが同じ処理になります。ちなみに、ascendingは昇順という意味です。
df.sort_values(by=['col0'])
df.sort_values(by=['col0'], ascending=Ture)![df.sort_values(by=['列名'])で列指定で昇順ソートした結果の表](https://prograshi.com/wp-content/uploads/2021/06/image-743.png)
列col0の要素で昇順ソートされています。
アルファベットや平仮名でも同様にソート可能です。
降順ソート
df.sort_values(by=[‘列名’], ascending=False)
オプションでascending=Falseを指定します。
df.sort_values(by=['col0'], ascending=False)![df.sort_values(by=['列名'], ascending=False)で列指定で降順ソートした結果の表](https://prograshi.com/wp-content/uploads/2021/06/image-744.png)
欠損値(NaN)を含む列のソート
欠損値(NaN)がソートの基準となる列に含まれている場合、ソート時にNaNを最上部 or 最下部のどちらに移動するか設定できます。
・na_position=’last’
└デフォルト(省略可)
└最下部へ移動
・na_position=’first’
└最上部へ移動
欠損値(NaN)を最下部へ移動NaNを含む列をソート
デフォルトの設定がna_position=’last’で欠損値(NaN)を最下部へ移動する処理なので、以下は同じ処理内容になります。
df.sort_values(by=['col1'])
df.sort_values(by=['col1'], na_position='last')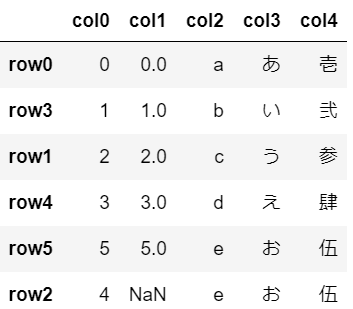
欠損値(NaN)を最上部へ移動NaNを含む列をソート
欠損値(NaN)NaNを最上部へ移動するソートはna_position=’first’を指定します。
df.sort_values(by=['col1'], na_position='first')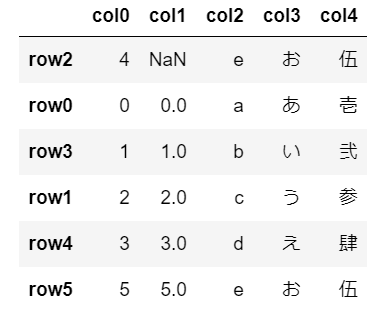
元の表を上書きする
sort_valuesの処理はデフォルトは非破壊のため、元の表は変更されずにそのまま残ります。
ですが、オプションの指定で上書きするように変更することもできます。デフォルトは上書きしない設定になっています。
・inplace=False
└デフォルト(省略可)
└上書きしない
・inplace=True
└上書きする
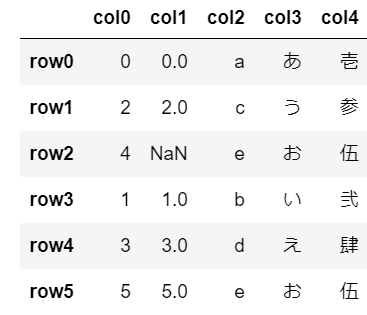
上書きしない(デフォルト)
デフォルトは上書きしない設定になっているので、以下の2つは同じ処理になります。
df.sort_values(by=['col1'])
df.sort_values(by=['col1'], inplace=False)元データの入っている変数dfに対してソートを実行し、dfをそのまま出力しています。
上書きする
上書きするにはオプションでinplace=Trueを指定します。
df.sort_values(by=['col1'], inplace=True)
df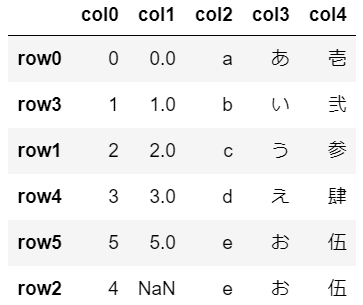
行を指定してソートする方法
行を指定してソートする場合は、行の要素を判定して列を並べ替えます。
列を指定する場合と異なり自由度が低く、数値のみがある表しかソートできません。
基本構文
sort_values(by=['行名'], axis=1)オプションに「axis=1」を記述することで、列を並べ替えることを指定しています。
- NaNや文字列を含む表はエラーになる。
- NaNや文字列を含まない行を指定してもエラーになる。(表の中に1つでも、NaNか文字列があれば機能しない)
ソートに使用する表
処理内容を紹介するにあたり、以下のような4行5列の表を使います。
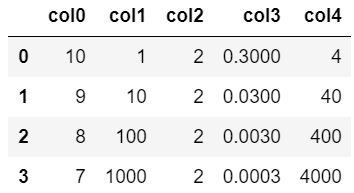
DataFrameで表を作成し、変数df2に格納しています。
import pandas as pd
col0 = [10, 9, 8, 7]
col1 = [1, 10, 100, 1000]
col2 = [2, 2, 2, 2]
col3 = [0.3, 0.03, 0.003, 0.0003]
col4 = [4, 40, 400, 4000]
df2 = pd.DataFrame(col0, columns=['col0'])
df2['col1'] = col1
df2['col2'] = col2
df2['col3'] = col3
df2['col4'] = col4
df2昇順ソート
デフォルト状態が昇順ソートになっています。ascending=Trueをつけても同じ処理になります。
df2.sort_values(by=[1], axis=1)
df2.sort_values(by=[1], axis=1, ascending=True)![df2.sort_values(by=[1], axis=1)による行指定の昇順ソート結果](https://prograshi.com/wp-content/uploads/2021/06/image-750.png)
降順ソート
降順ソートはオプションでascending=Falseを指定します。
df2.sort_values(by=[1], axis=1, ascending=False)![df2.sort_values(by=[1], axis=1, ascending=False)による行の降順ソート結果](https://prograshi.com/wp-content/uploads/2021/06/image-751.png)
参考
Pandas公式 DataFrameのsort_valuesメソッド(英語)
なお、表をソートするメソッドにはsort_indexメソッドもありますが、こちらは非推奨となっています。
FutureWarning: by argument to sort_index is deprecated, please use .sort_values(by=…)
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.sort_values.html

