

PythonのPandasモジュールのDataFrameオブジェクトで作成済みの表やテーブルに対して、後から新たに列や行を追加する方法について実例を用いて解説しています。
はじめに(ベースとなる表)
行や列を追加する前の元の表として、以下の3行3列表データを使います。
作成した表は変数dfに格納。
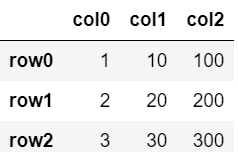
row0 = [1, 2, 3]
row1 = [10, 20, 30]
row2 = [100, 200, 300]
df = pd.DataFrame([row0,row1,row2], columns=['col0','col1','col2'])
df.index = ['row0', 'row1', 'row2']
df列の追加
直感的に使いやすいのは、df[‘列名‘] と assign。
・df[‘列名’]
・assignメソッド
・joinメソッド
・concat関数
df[‘列名‘]
df[‘列名‘] = B
└「df」:元の表
└「B」:追加する内容
※既存の行名を指定すると上書きされる。
追加する内容の指定は比較的自由。
数値、値、表データ、数式、listなどが使える。
▼事例
①列の追加(list)
②列の追加(数値)
③列の追加(表)
④列の追加(数式)
①列の追加(list)
df['col3'] = [4, 40, 400]
df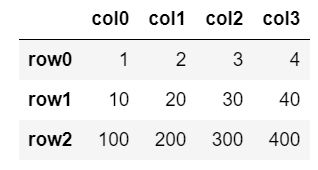
②列の追加(数値)
df['col3'] = 4
df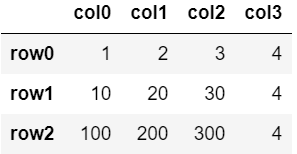
③列の追加(表)
df['col3'] = df['col2']
df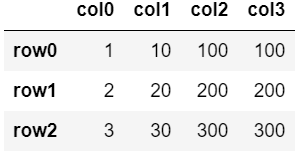
④列の追加(数式)
df['col3'] = df['col2'] * 100
df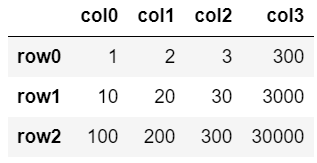
assignメソッド
assignメソッドで列名を指定して追加することもできる。
df.assign(列名A=[a,b,,], 列名B=[c,d,,],,)
└「列名A」「列名B」:追加する列名
└「a,b,,」「c,d,,」:各列の中身
・上書きされない
・列名はクオテーション不要
・要素をlistで指定する場合はベースとなる表の行数と一致していること
・列名にクオテーションがある
SyntaxError: expression cannot contain assignment, perhaps you meant “==”?
・列名がない
TypeError: assign() takes 1 positional argument but 2 were given
・listの要素数が合わない
ValueError: Length of values does not match length of index
▼1列追加
df.assign(A=[1,2,3])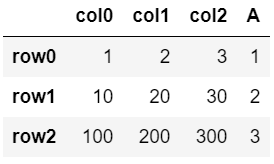
▼1列追加(表データ・数式)
df.assign(A=df['col0']*100)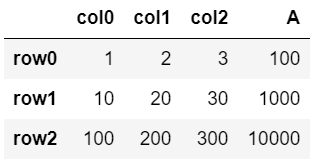
▼2列追加
df.assign(A=[1,2,3], B=100)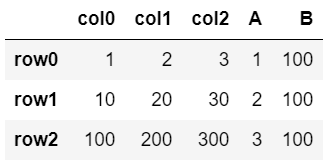
「列名=中身」を付け加えればその分列が増える。
joinメソッド
joinメソッドは表を結合する場合に使える。
listや数値など行番号(index)を持たないものには使えない。
join(dfA, rsuffix=’_a’)
└「dfA」:結合する表
└「rsuffix=’_a’」:列名が重複する場合は、追加した列名に「_a」(任意)をつける。
*「lsuffix=’_a’」の場合は既存の列名を変更。
▼事例
追加する表のパターン別に処理を確認。
①行名がすべて同じ表を追加(列名重複なし)
②存在しない行名がある表を追加
③列名が重複する場合
④一部の列名が重複する場合
①行名がすべて同じ表を追加(列名重複なし)
行名がベースとなる表の行名と一致し、列名が既存と重複しない場合。
dfA = pd.DataFrame([100,200,300])
dfA.index = ['row0', 'row1', 'row2']
dfA
▼追加
df.join(dfA)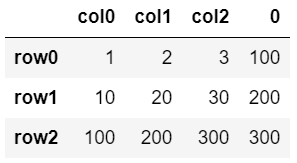
新規列が追加された。
②存在しない行名がある表を追加
ベースの表に存在しない行名がある場合
└ベースの表に新たに行は追加されない。
└行名が一致しないデータはNaN(欠損値)となる。
▼追加する表
row0のみが存在。XXX、YYYはベースの表にはない。
dfB = pd.DataFrame([100,200,300])
dfB.index = ['row0', 'XXX', 'YYY']
dfB
▼追加
df.join(dfB)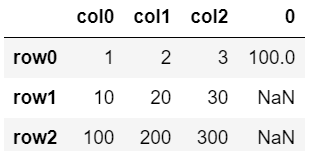
③列名が重複する場合
join(dfA, rsuffix=’_a’)
列名が重複する場合、「rsuffix=’_a’」で重複する列名につける末尾の文字を指定。
▼オプション
・「rsuffix=’_a’」:追加する重複した列名に指定した文字を追加(right suffixの略)
・「lsuffix=’_a’」:既存の重複した列名に指定した文字を追加(left suffixの略)
指定しないとエラーになる。
▼追加する表
既存の表と同じ列名(col0)を含む表。
dfC = pd.DataFrame([100,200,300], columns=['col0'])
dfC.index = ['row0', 'row1', 'XXX']
dfC
▼追加(rsuffixの場合)
df.join(dfC, rsuffix='_@')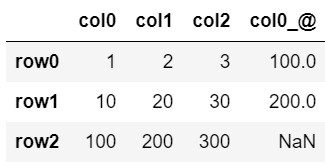
▼追加(lsuffixの場合)
df.join(dfC, lsuffix='_@')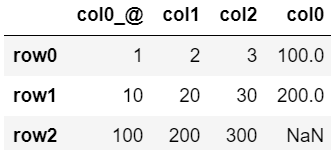
④一部の列名が重複する場合
処理は③の列名が重複する場合と同じ。
・重複する列は列名に指定したsuffixがつく。
・重複しない列は列名がそのままで追加される。
▼追加する表
既存の表と同じ列名(col0, col1)を含む表。
list1 = [100,200,300]
list2 = ['A','B','C']
list3 = ['AAA','BBB','CCC']
list4 = ['10A','20B','30C']
dfD = pd.DataFrame([list1,list2, list3, list4], columns=['col0', 111,'col1'])
dfD.index = ['row0', 'row1', 'XXX', 'YYY']
dfD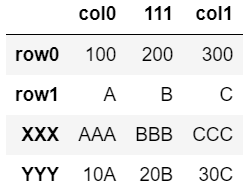
▼追加
df.join(dfD, rsuffix='_@')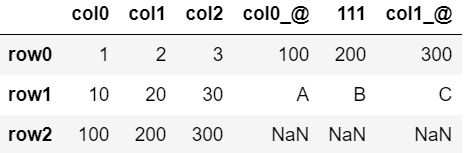
- 重複する列名には指定した文字列が追加
- ベースの表に存在しない行は追加されない
- 追加する列で、存在しなかった行にはNaNが入る
concat関数(列の追加)
concat関数を使って表同士を結合。
pd.concat([df, dfA], axis=1)
└「df」:ベースとなる表
└「dfA」:追加する表
└「axis=1」:列を追加する指示
・列名が重複していてもそのまま追加
・行名が異なる場合は新規行を追加(デフォルト:join=’outer’)
・join=’inner’オプションで、行名が一致するもののみ残す
- デフォルト(オプション無し)
- axis=1
- sortオプション
- joinオプション
・listや数値の結合はできない
-TypeError: cannot concatenate object of type ”; only Series and DataFrame objs are valid
・「concat」の意味
concatinate: 結合する。連結する。
結合の元となる表
下記3行3列の表「dfA」を使用。
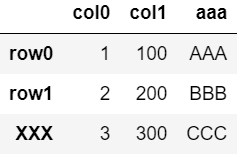
・列「col0」「col1」はベースの表と重複。
・行「xxx」はベースの表にない結合する表
list1 = [1,100,'AAA']
list2 = [2,200,'BBB']
list3 = [3,300,'CCC']
dfE = pd.DataFrame([list1,list2, list3], columns=['col0', 'col1', 'aaa'])
dfE.index = ['row0', 'row1', 'XXX']
dfE列の追加はaxis=1の指定が必須
pd.concat([df, dfA], axis=1)
列の追加をする場合「axis=1」は必須。つけないと行方向に追加となり結果が大きく異る。
▼「axis=1」あり
pd.concat([df, dfA], axis=1)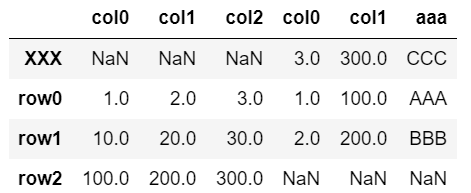
・列を追加
・列名が重複していてもそのまま追加(joinメソッドとは異なる)
・追加する表にない行の値はNaNになる。
・ベースの表にない行は新たに追加。
▼「axis=1」なし
「axis=0」が省略された形。
行方向に結合することになる。
pd.concat([df, dfA])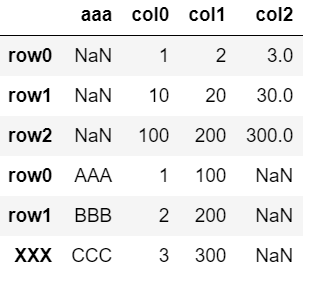
・列名が一致しない場合は新たに列を追加。
・行名が重複していてもすべて新たに追加。
※列は追加されるが行が統合されないため、実行したい内容と異なる。
sortオプション(列)
sortオプションを指定せずに表を結合すると、行名で自動ソートされる。
└デフォルト:sort=True
▼sort=True(デフォルト)
sort=Trueはデフォルトで設定されているので以下2つは同じ処理になる。
pd.concat([df, dfA], axis=1)
pd.concat([df, dfA], axis=1, sort=True)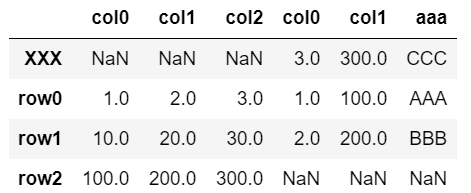
行「XXX」が自動ソートで上にくる。
▼sort=False
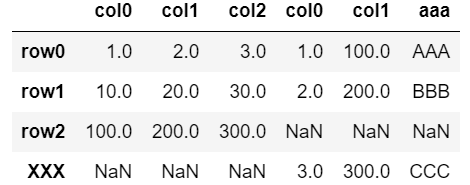
pd.concat([df, dfA], axis=1, sort=False)「sort=False」を記述すると追加した行は最後尾に追加される。
▼ベースとなる表を入れ替えた場合
pd.concat([dfA, df], axis=1, sort=False)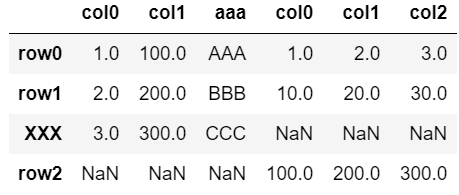
ベースとなる「dfA」に存在しない行が、末尾に追加される。
joinオプション(列)
行の処理を決める(axis=1の場合)
join=’outer’
└デフォルトの設定。
└存在しない行を残す。
join=’inner’
└重複する行のみ残す。
▼join=’outer’
join=’outer’はデフォルトで設定されているので以下2つは同じ処理になる。
pd.concat([dfA, df], axis=1)
pd.concat([dfA, df], axis=1, join='outer')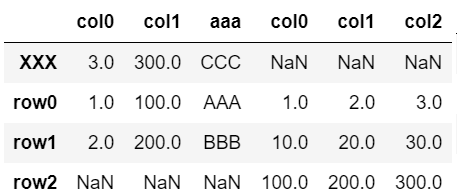
結合前後で存在しない行「XXX」が追加される。
▼join=’inner’
pd.concat([dfA, df], axis=1, join='inner')
どちらかにしか存在しない行「row2」「XXX」は削除。
行の追加
- locメソッド
- concat関数
直感的に使いやすいのはlocメソッド。
locメソッド
df.loc[‘A’]=B
└「df」:元の表
└「A」:追加する行の名前
└「B」:追加する内容
※既存の行名を指定すると上書きされる。
追加する内容の指定は比較的自由。
数値、値、表データ、数式、listなどが使える。
①行の追加(list)
②行の追加(数値)
③行の追加(表)
④行の追加(数式)
①行の追加(list)
df.loc['AAA'] = [4, 40, 400]
df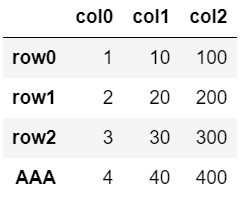
②行の追加(数値)
df.loc['AAA'] = 4
df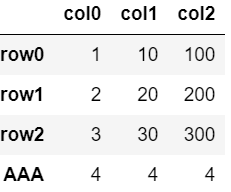
③行の追加(表)
df.loc['AAA'] = df.loc['row2']
df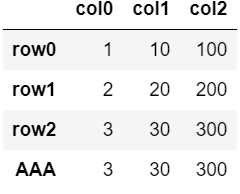
④行の追加(数式)
df.loc['AAA'] = df.loc['row2'] * 100
df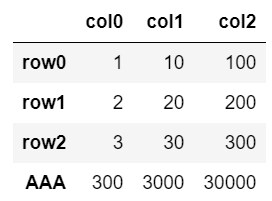
concat関数(行の追加)
concat関数を使って表同士を結合。
pd.concat([df, dfA])
└「df」:ベースとなる表
└「dfA」:追加する表
・行名が重複していてもそのまま追加
・列名が異なる場合は新規列を追加(デフォルト:join=’outer’)
・join=’inner’オプションで、列名が一致するもののみ残す
- デフォルト(オプション無し)
- sortオプション
- joinオプション
・listや数値の結合はできない
-TypeError: cannot concatenate object of type ”; only Series and DataFrame objs are valid
・「concat」の意味
concatinate: 結合する。連結する。
結合の元となる表
下記2行3列の表を変数「dfA」に格納したものを使用。
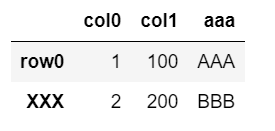
list1 = [1,100,'AAA']
list2 = [2,200,'BBB']
dfA = pd.DataFrame([list1,list2], columns=['col0', 'col1', 'aaa'])
dfA.index = ['row0', 'XXX']
dfAデフォルト(オプション無し)
pd.concat([df, dfA])
pd.concat([df, dfA])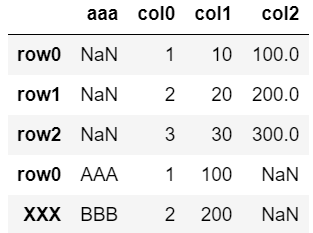
・行名が重複していてもすべて新たに追加。
・一致しない列名は新たに列を追加。
・該当しないセルはNaN(欠損値)で埋められる
sortオプション(行)
sortオプションを指定せずに表を結合すると、列名で自動ソートされる。
└デフォルト:sort=True
▼sort=True(デフォルト)
デフォルトでTrueに設定されているので以下2つは同じ処理になる。
pd.concat([df, dfA])
pd.concat([df, dfA], sort=True)後から追加した「aaa」列が自動ソートで先頭にくる。
▼sort=False
pd.concat([df, dfA], sort=False)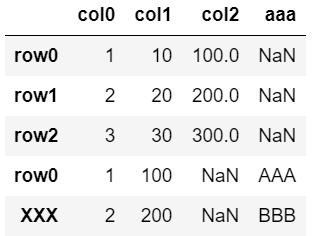
後から追加した「aaa」列は最後尾に結合。
joinオプション(行)
列の処理を決める。
join=’outer’
└デフォルトの設定。
└存在しない列を残す。
join=’inner’
└重複する列のみ残す。
▼join=’outer’(デフォルト)
デフォルトでjoin=’outer’になっているので以下2つは同じ。
pd.concat([df, dfA])
pd.concat([df, dfA], join='outer')結合前後の表に存在しない列「aaa」が残る。
▼join=’inner’
pd.concat([df, dfA], join='inner')

結合前後の双方の表に存在する列のみ残る。

