

GoogleのBigQueryを使うと超大量データを高速処理できるテーブルを作成することができます。作り方はとてもシンプルです。
あるプロジェクトで自分のテーブルを作成する方法についてメモ程度にまとめています。
テーブルの作成
まずはプロジェクトの右端にある3点を右クリックして「テーブル作成」を選択します。
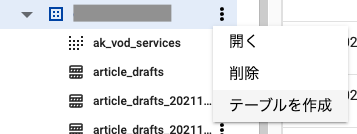
画面右側にテーブルの詳細を入力する欄ができるので、テーブル名を入力します。
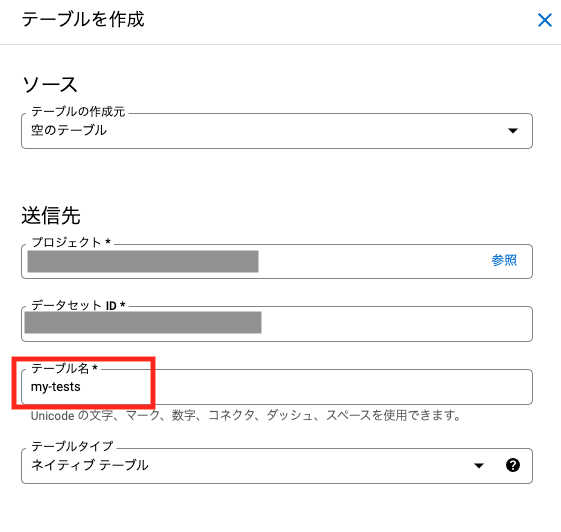
スキーマの編集
次にテーブルの構造となるスキーマを指定します。
スキーマは外部でjsonファイルを作ってそれをベースに作成することもできますし、画面上で直接入力することもできます。
ここでは画面上で直接入力します。
スキーマ項目の「テキストとして編集」をONにし、JSON形式でスキーマを貼り付けます。

ここでは次のようにしました。設定項目は次の4つです。
| キー名 | 内容 |
|---|---|
| name | カラム名 |
| type | 型 |
| mode | オプションを設定 |
| description | 説明 |
type
typeで指定できる型は次のようになっています。
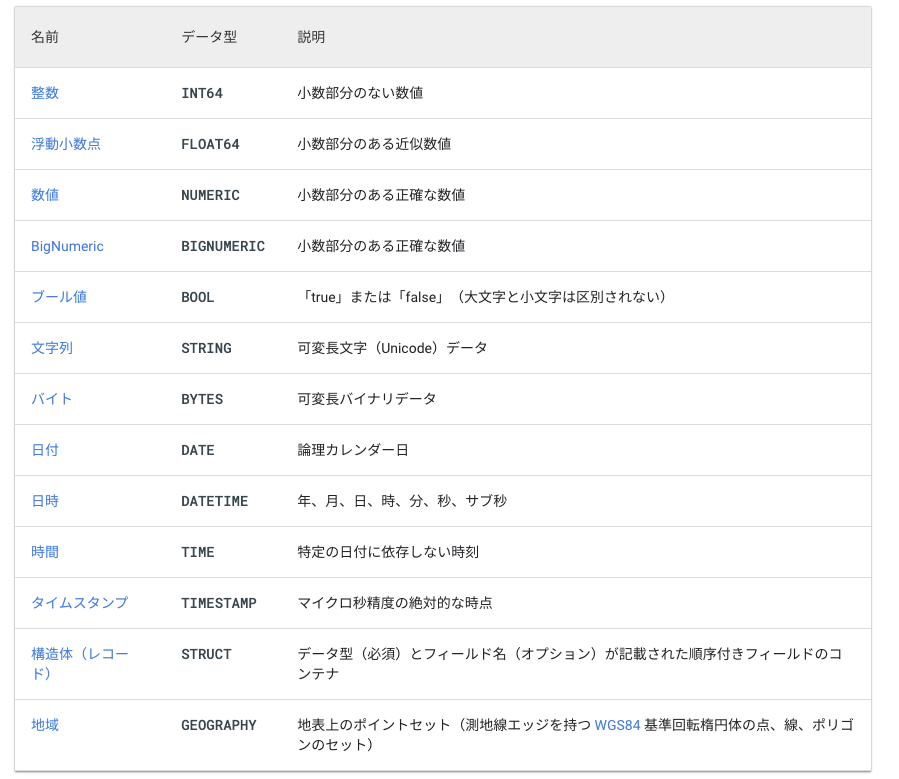
必須要件として、DATE, TIMESTAMP, DATETUMEのいずれかの列を含んでいる必要があります。
model
モデルでは各カラムのオプションを設定します。設定できるのは次の3つです。指定がない場合はNULLABLEになります。
| mode | 内容 |
|---|---|
| NULLABLE | nullを許可する |
| REQUIRED | 必須 |
| REPEATED | 配列形式で保存 |
description
カラムのdescriptionは説明です。必要に応じて設定できます。
設定例
ここでは次のように設定しています。
[
{
"name": "inserted_at",
"type": "DATE",
"mode": "REQUIRED"
},
{
"name": "user_id",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "user_name",
"type": "STRING",
"mode": "REQUIRED",
"description": "user name"
},
{
"name": "hobby",
"type": "STRING",
"mode": "REPEATED",
"description": "multiplu inputs are possible"
},
{
"name": "gender",
"type": "STRING",
"mode": "NULLABLE"
}
]パーティショニングの設定
パーティショニングとは?
BigQueryにはパーティショニングという概念があります。
BigQueryでは大量のデータを扱うため、検索を早くするために検索対象となるテーブルを切り出して管理りします。これがパーティショニングの概念です。
パーティショニングをしないと、WHERE句であるデータを指定した場合に、対象のデータが出てくるまで上から全てのデータを一つずつ見ていくことになり、レスポンスが大変遅くなってしまいます。
このため、基本的にパーティショニングの設定は必須です。
パーティショニングは設定したカラムの型もよりますが、「取り込み時間により分割」と「フィールドにより分割」の2つから選択することができます。
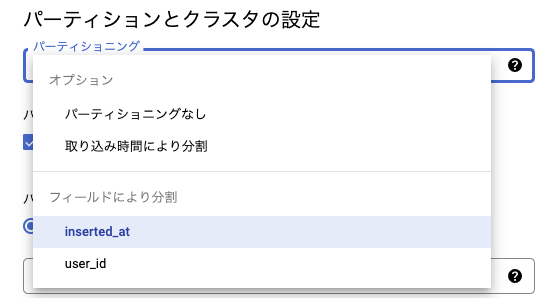
フィールドにより分割
フィールドにより分割はカラムにDATE、TUMESTAMP、DATETIMEのいずれか、またはINTEGERが含まれている場合に選択可能になります。
DATE、TUMESTAMP、DATETIMEの場合は、1日、1週間といった単位で選びます。INTEGERの場合は整数範囲を指定します。
パーティショニングフィルタでWHERE句を必須にする
パーティショニングフィルタでは「データのクエリで WHERE 句を必須にする」項目があります。
これにチェックを入れるとBigQueryに投げるクエリにはWHERE句が含まれていないと実行されなくなります。
こうすることで、大量のデータを請求することを防ぎます。基本的にはチェックを入れます。

パーティショニングタイプ
選択したパーティショニングタイプによってパーティショニングの範囲を選ぶことができます。
日付を選択した場合は以下のように、日や週などで選べます。データ取得の頻度に合わせて設定します。
Dailyのデータ更新なら1日、Weeklyのデータ更新なら1週間とします。

詳細オプション
詳細オプションは基本デフォルトのままでOKです。

以上で設定は完了です。
「テーブルを作成」をクリックすれば、テーブルが生成されます。
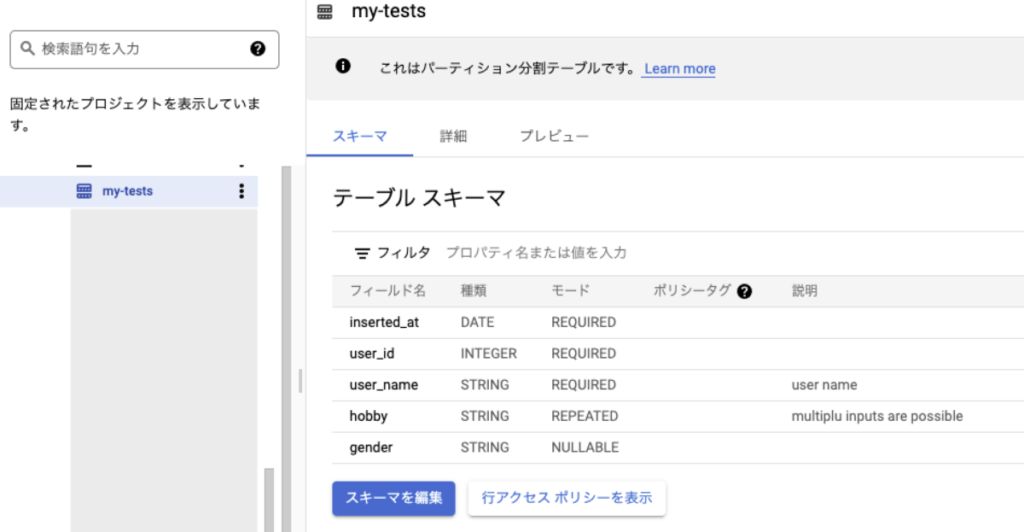
作成したテーブル
作成したテーブルは次のようになります。
データを挿入する
BigQueryのコンソール上で作成したテーブルに対してデータを挿入することができます。
画面右上にある「クエリを新規作成」をクリックします。

SQLのINSERT INTOを使ってデータを挿入できます。
INSERT INTO `テーブル名` (カラム名1, カラム名2,,,,) VALUES (値1, 値2,,,) 全てのカラムに入力する場合は、テーブル名の後ろのカラム名の引数を省略できます。
- テーブル名はBigQuery固有のものです。通常エディタを新規作成した時にSLECT文の中に記載されています。
- スキーマを作成した時に設定したタイプ(型)以外を入力すると赤色でエラーが表示されます。
実例
全てのカラムに値を挿入する場合は次のようになります。
INSERT INTO `xxx.yyy.my-tests` VALUES ('2021-11-11', 1, 'test_user', ['running'], 'male') 
すると、テーブルの「プレビュー」タブでデータが挿入されていることが確認できます。

※データが反映されていない場合はリロードしてください。
以上でテーブルの生成とデータ入力は完了です。

